Latent Space Exploration with Randomized Sparse Mixed Scale Autoencoders, regularized by the availability of image labels¶
Authors: Eric Roberts and Petrus Zwart
E-mail: PHZwart@lbl.gov, EJRoberts@lbl.gov ___
This notebook highlights some basic functionality with the pyMSDtorch package.
In this notebook we setup autoencoders, with the goal to explore the latent space it generates. In this case however, we will guide the formation of the latent space by including labels to specific images.
The autoencoders we use are based on randomly construct convolutional neural networks in which we can control the number of parameters it contains. This type of control can be beneficial when the amount of data on which one can train a network is not very voluminous, as it allows for better handles on overfitting.
The constructed latent space can be used for unsupervised and supervised exploration methods. In our limited experience, the classifiers that are trained come out of the data are reasonable, but can be improved upon using classic classification methods, as shown further.
[1]:
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from pyMSDtorch.core import helpers
from pyMSDtorch.core import train_scripts
from pyMSDtorch.core.networks import SparseNet
from pyMSDtorch.test_data.twoD import random_shapes
from pyMSDtorch.core.utils import latent_space_viewer
from pyMSDtorch.viz_tools import plots
from pyMSDtorch.viz_tools import plot_autoencoder_image_classification as paic
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader, TensorDataset
import einops
import umap
<frozen importlib._bootstrap>:219: RuntimeWarning: scipy._lib.messagestream.MessageStream size changed, may indicate binary incompatibility. Expected 56 from C header, got 64 from PyObject
Create some data first
[2]:
N_train = 500
N_labeled = 100
N_test = 500
noise_level = 0.150
Nxy = 32
train_data = random_shapes.build_random_shape_set_numpy(n_imgs=N_train,
noise_level=noise_level,
n_xy=Nxy)
test_data = random_shapes.build_random_shape_set_numpy(n_imgs=N_test,
noise_level=noise_level,
n_xy=Nxy)
[3]:
plots.plot_shapes_data_numpy(train_data)
[4]:
which_one = "Noisy" #"GroundTruth"
batch_size = 100
loader_params = {'batch_size': batch_size,
'shuffle': True}
train_imgs = torch.Tensor(train_data[which_one]).unsqueeze(1)
train_labels = torch.Tensor(train_data["Label"]).unsqueeze(1)-1
train_labels[N_labeled:]=-1 # remove some labels to highlight 'mixed' training
Ttrain_data = TensorDataset(train_imgs,train_labels)
train_loader = DataLoader(Ttrain_data, **loader_params)
loader_params = {'batch_size': batch_size,
'shuffle': False}
test_images = torch.Tensor(test_data[which_one]).unsqueeze(1)
test_labels = torch.Tensor(test_data["Label"]).unsqueeze(1)-1
Ttest_data = TensorDataset( test_images, test_labels )
test_loader = DataLoader(Ttest_data, **loader_params)
Lets build an autoencoder first.
There are a number of parameters to play with that impact the size of the network:
- latent_shape: the spatial footprint of the image in latent space.
I don't recommend going below 4x4, because it interferes with the
dilation choices. This is a bit of a annoyiong feature, we need to fix that.
Its on the list.
- out_channels: the number of channels of the latent image. Determines the
dimension of latent space: (channels,latent_shape[-2], latent_shape[-1])
- depth: the depth of the random sparse convolutional encoder / decoder
- hidden channels: The number of channels put out per convolution.
- max_degree / min_degree : This determines how many connections you have per node.
Other parameters do not impact the size of the network dramatically / at all:
- in_shape: determined by the input shape of the image.
- dilations: the maximum dilation should not exceed the smallest image dimension.
- alpha_range: determines the type of graphs (wide vs skinny). When alpha is large,
the chances for skinny graphs to be generated increases.
We don't know which parameter choice is best, so we randomize it's choice.
- gamma_range: no effect unless the maximum degree and min_degree are far apart.
We don't know which parameter choice is best, so we randomize it's choice.
- pIL,pLO,IO: keep as is.
- stride_base: make sure your latent image size can be generated from the in_shape
by repeated division of with this number.
For the classification, specify the number of output classes. Here we work with 4 shapes, so set it to 4. The dropout rate governs the dropout layers in the classifier part of the networks and doesn’t affect the autoencoder part.
[5]:
autoencoder = SparseNet.SparseAEC(in_shape=(32, 32),
latent_shape=(4, 4),
out_classes=4,
depth=40,
dilations=[1,2,3],
hidden_channels=3,
out_channels=2,
alpha_range=(0.5, 1.0),
gamma_range=(0.0, 0.5),
max_degree=10, min_degree=10,
pIL=0.15,
pLO=0.15,
IO=False,
stride_base=2,
dropout_rate=0.05,)
pytorch_total_params = helpers.count_parameters(autoencoder)
print( "Number of parameters:", pytorch_total_params)
Number of parameters: 372778
We define two optimizers, one for autoencoding and one for classification. They will be minimized consequetively instead of building a single sum of targets. This avoids choosing the right weight. The mini-epochs are the number of epochs it passes over the whole data set to optimize a single atrget function. The autoencoder is done first.
[6]:
torch.cuda.empty_cache()
learning_rate = 1e-3
num_epochs=50
criterion_AE = nn.MSELoss()
optimizer_AE = optim.Adam(autoencoder.parameters(), lr=learning_rate)
criterion_label = nn.CrossEntropyLoss(ignore_index=-1)
optimizer_label = optim.Adam(autoencoder.parameters(), lr=learning_rate)
rv = train_scripts.autoencode_and_classify_training(net=autoencoder.to('cuda:0'),
trainloader=train_loader,
validationloader=test_loader,
macro_epochs=num_epochs,
mini_epochs=5,
criteria_autoencode=criterion_AE,
minimizer_autoencode=optimizer_AE,
criteria_classify=criterion_label,
minimizer_classify=optimizer_label,
device="cuda:0",
show=1,
clip_value=100.0)
Epoch 1, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 2.5833e-01 | Validation Loss : 1.9714e-01
Training CC : 0.1946 | Validation CC : 0.4514
** Classification Losses **
Training Loss : 1.4542e+00 | Validation Loss : 1.4837e+00
Training F1 Macro: 0.1412 | Validation F1 Macro : 0.1729
Training F1 Micro: 0.2659 | Validation F1 Micro : 0.2720
Epoch 1, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.7494e-01 | Validation Loss : 1.3841e-01
Training CC : 0.5357 | Validation CC : 0.6173
** Classification Losses **
Training Loss : 1.4567e+00 | Validation Loss : 1.5082e+00
Training F1 Macro: 0.1078 | Validation F1 Macro : 0.1527
Training F1 Micro: 0.2518 | Validation F1 Micro : 0.2580
Epoch 1, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.2557e-01 | Validation Loss : 1.0217e-01
Training CC : 0.6537 | Validation CC : 0.6885
** Classification Losses **
Training Loss : 1.5433e+00 | Validation Loss : 1.5206e+00
Training F1 Macro: 0.1070 | Validation F1 Macro : 0.1454
Training F1 Micro: 0.2443 | Validation F1 Micro : 0.2580
Epoch 1, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 9.3322e-02 | Validation Loss : 7.6507e-02
Training CC : 0.7179 | Validation CC : 0.7457
** Classification Losses **
Training Loss : 1.5297e+00 | Validation Loss : 1.5298e+00
Training F1 Macro: 0.1070 | Validation F1 Macro : 0.1338
Training F1 Micro: 0.2436 | Validation F1 Micro : 0.2480
Epoch 1, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.9479e-02 | Validation Loss : 5.7264e-02
Training CC : 0.7750 | Validation CC : 0.8002
** Classification Losses **
Training Loss : 1.5637e+00 | Validation Loss : 1.5268e+00
Training F1 Macro: 0.0887 | Validation F1 Macro : 0.1491
Training F1 Micro: 0.2143 | Validation F1 Micro : 0.2560
Epoch 2, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.9107e-02 | Validation Loss : 6.3066e-02
Training CC : 0.8004 | Validation CC : 0.7721
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.4098e+00 | Validation Loss : 1.2859e+00
Training F1 Macro: 0.1368 | Validation F1 Macro : 0.2642
Training F1 Micro: 0.2651 | Validation F1 Micro : 0.3360
Epoch 2, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 6.6844e-02 | Validation Loss : 7.0438e-02
Training CC : 0.7638 | Validation CC : 0.7362
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.1472e+00 | Validation Loss : 1.1916e+00
Training F1 Macro: 0.4144 | Validation F1 Macro : 0.3684
Training F1 Micro: 0.4584 | Validation F1 Micro : 0.4100
Epoch 2, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 7.1455e-02 | Validation Loss : 7.2273e-02
Training CC : 0.7415 | Validation CC : 0.7272
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.0518e+00 | Validation Loss : 1.1435e+00
Training F1 Macro: 0.5795 | Validation F1 Macro : 0.4515
Training F1 Micro: 0.5803 | Validation F1 Micro : 0.4740
Epoch 2, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 7.3640e-02 | Validation Loss : 7.4967e-02
Training CC : 0.7305 | Validation CC : 0.7132
** Classification Losses ** <---- Now Optimizing
Training Loss : 9.1016e-01 | Validation Loss : 1.0982e+00
Training F1 Macro: 0.6049 | Validation F1 Macro : 0.5148
Training F1 Micro: 0.6839 | Validation F1 Micro : 0.5260
Epoch 2, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 7.5467e-02 | Validation Loss : 7.6074e-02
Training CC : 0.7207 | Validation CC : 0.7064
** Classification Losses ** <---- Now Optimizing
Training Loss : 8.3661e-01 | Validation Loss : 1.0611e+00
Training F1 Macro: 0.7700 | Validation F1 Macro : 0.5408
Training F1 Micro: 0.7678 | Validation F1 Micro : 0.5460
Epoch 3, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.2492e-02 | Validation Loss : 4.8532e-02
Training CC : 0.7748 | Validation CC : 0.8198
** Classification Losses **
Training Loss : 8.0198e-01 | Validation Loss : 1.1293e+00
Training F1 Macro: 0.7082 | Validation F1 Macro : 0.4957
Training F1 Micro: 0.7186 | Validation F1 Micro : 0.5080
Epoch 3, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.3980e-02 | Validation Loss : 3.8473e-02
Training CC : 0.8411 | Validation CC : 0.8520
** Classification Losses **
Training Loss : 9.4166e-01 | Validation Loss : 1.1996e+00
Training F1 Macro: 0.5814 | Validation F1 Macro : 0.3834
Training F1 Micro: 0.6267 | Validation F1 Micro : 0.4200
Epoch 3, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 3.5708e-02 | Validation Loss : 3.3619e-02
Training CC : 0.8654 | Validation CC : 0.8676
** Classification Losses **
Training Loss : 1.0400e+00 | Validation Loss : 1.2227e+00
Training F1 Macro: 0.4950 | Validation F1 Macro : 0.3565
Training F1 Micro: 0.5396 | Validation F1 Micro : 0.4020
Epoch 3, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 3.1166e-02 | Validation Loss : 3.1066e-02
Training CC : 0.8803 | Validation CC : 0.8788
** Classification Losses **
Training Loss : 1.1217e+00 | Validation Loss : 1.2409e+00
Training F1 Macro: 0.4504 | Validation F1 Macro : 0.3344
Training F1 Micro: 0.4988 | Validation F1 Micro : 0.3880
Epoch 3, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 2.8666e-02 | Validation Loss : 2.9292e-02
Training CC : 0.8904 | Validation CC : 0.8869
** Classification Losses **
Training Loss : 1.0885e+00 | Validation Loss : 1.2616e+00
Training F1 Macro: 0.4854 | Validation F1 Macro : 0.3249
Training F1 Micro: 0.5238 | Validation F1 Micro : 0.3840
Epoch 4, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 2.7689e-02 | Validation Loss : 3.1067e-02
Training CC : 0.8944 | Validation CC : 0.8795
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.1196e+00 | Validation Loss : 1.1489e+00
Training F1 Macro: 0.4359 | Validation F1 Macro : 0.4688
Training F1 Micro: 0.5154 | Validation F1 Micro : 0.4900
Epoch 4, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 3.1510e-02 | Validation Loss : 3.6835e-02
Training CC : 0.8790 | Validation CC : 0.8557
** Classification Losses ** <---- Now Optimizing
Training Loss : 9.0130e-01 | Validation Loss : 1.0439e+00
Training F1 Macro: 0.7237 | Validation F1 Macro : 0.5512
Training F1 Micro: 0.7267 | Validation F1 Micro : 0.5600
Epoch 4, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 3.6501e-02 | Validation Loss : 3.8769e-02
Training CC : 0.8585 | Validation CC : 0.8474
** Classification Losses ** <---- Now Optimizing
Training Loss : 7.4278e-01 | Validation Loss : 1.0212e+00
Training F1 Macro: 0.8133 | Validation F1 Macro : 0.5642
Training F1 Micro: 0.8138 | Validation F1 Micro : 0.5640
Epoch 4, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 3.7923e-02 | Validation Loss : 3.9381e-02
Training CC : 0.8527 | Validation CC : 0.8445
** Classification Losses ** <---- Now Optimizing
Training Loss : 6.4941e-01 | Validation Loss : 9.9847e-01
Training F1 Macro: 0.8295 | Validation F1 Macro : 0.5819
Training F1 Micro: 0.8402 | Validation F1 Micro : 0.5800
Epoch 4, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 3.9013e-02 | Validation Loss : 4.0582e-02
Training CC : 0.8479 | Validation CC : 0.8393
** Classification Losses ** <---- Now Optimizing
Training Loss : 6.9050e-01 | Validation Loss : 9.9734e-01
Training F1 Macro: 0.7857 | Validation F1 Macro : 0.5757
Training F1 Micro: 0.7938 | Validation F1 Micro : 0.5860
Epoch 5, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 3.3743e-02 | Validation Loss : 3.1420e-02
Training CC : 0.8697 | Validation CC : 0.8789
** Classification Losses **
Training Loss : 6.3096e-01 | Validation Loss : 1.0156e+00
Training F1 Macro: 0.8209 | Validation F1 Macro : 0.5716
Training F1 Micro: 0.8429 | Validation F1 Micro : 0.5840
Epoch 5, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 2.8137e-02 | Validation Loss : 2.8415e-02
Training CC : 0.8927 | Validation CC : 0.8895
** Classification Losses **
Training Loss : 6.2693e-01 | Validation Loss : 1.0242e+00
Training F1 Macro: 0.8346 | Validation F1 Macro : 0.5789
Training F1 Micro: 0.8430 | Validation F1 Micro : 0.5900
Epoch 5, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 2.5760e-02 | Validation Loss : 2.6215e-02
Training CC : 0.9017 | Validation CC : 0.8982
** Classification Losses **
Training Loss : 7.1689e-01 | Validation Loss : 1.0248e+00
Training F1 Macro: 0.8085 | Validation F1 Macro : 0.5630
Training F1 Micro: 0.8148 | Validation F1 Micro : 0.5760
Epoch 5, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 2.3933e-02 | Validation Loss : 2.4485e-02
Training CC : 0.9091 | Validation CC : 0.9046
** Classification Losses **
Training Loss : 7.3269e-01 | Validation Loss : 1.0355e+00
Training F1 Macro: 0.8173 | Validation F1 Macro : 0.5564
Training F1 Micro: 0.8179 | Validation F1 Micro : 0.5680
Epoch 5, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 2.2497e-02 | Validation Loss : 2.3630e-02
Training CC : 0.9148 | Validation CC : 0.9083
** Classification Losses **
Training Loss : 7.4537e-01 | Validation Loss : 1.0341e+00
Training F1 Macro: 0.8470 | Validation F1 Macro : 0.5483
Training F1 Micro: 0.8414 | Validation F1 Micro : 0.5560
Epoch 6, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 2.1940e-02 | Validation Loss : 2.4573e-02
Training CC : 0.9168 | Validation CC : 0.9045
** Classification Losses ** <---- Now Optimizing
Training Loss : 7.0182e-01 | Validation Loss : 9.8734e-01
Training F1 Macro: 0.8343 | Validation F1 Macro : 0.5737
Training F1 Micro: 0.8300 | Validation F1 Micro : 0.5840
Epoch 6, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 2.3738e-02 | Validation Loss : 2.6494e-02
Training CC : 0.9096 | Validation CC : 0.8966
** Classification Losses ** <---- Now Optimizing
Training Loss : 5.7709e-01 | Validation Loss : 9.7654e-01
Training F1 Macro: 0.8604 | Validation F1 Macro : 0.5669
Training F1 Micro: 0.8608 | Validation F1 Micro : 0.5740
Epoch 6, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 2.5391e-02 | Validation Loss : 2.7516e-02
Training CC : 0.9030 | Validation CC : 0.8923
** Classification Losses ** <---- Now Optimizing
Training Loss : 5.5142e-01 | Validation Loss : 9.4373e-01
Training F1 Macro: 0.7920 | Validation F1 Macro : 0.6263
Training F1 Micro: 0.8294 | Validation F1 Micro : 0.6320
Epoch 6, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 2.6273e-02 | Validation Loss : 2.8650e-02
Training CC : 0.8990 | Validation CC : 0.8876
** Classification Losses ** <---- Now Optimizing
Training Loss : 5.3247e-01 | Validation Loss : 9.5497e-01
Training F1 Macro: 0.8407 | Validation F1 Macro : 0.6279
Training F1 Micro: 0.8674 | Validation F1 Micro : 0.6220
Epoch 6, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 2.7523e-02 | Validation Loss : 2.9696e-02
Training CC : 0.8941 | Validation CC : 0.8833
** Classification Losses ** <---- Now Optimizing
Training Loss : 4.0847e-01 | Validation Loss : 9.5333e-01
Training F1 Macro: 0.9402 | Validation F1 Macro : 0.6296
Training F1 Micro: 0.9391 | Validation F1 Micro : 0.6200
Epoch 7, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 2.5244e-02 | Validation Loss : 2.4720e-02
Training CC : 0.9038 | Validation CC : 0.9037
** Classification Losses **
Training Loss : 3.8517e-01 | Validation Loss : 9.4221e-01
Training F1 Macro: 0.9235 | Validation F1 Macro : 0.6441
Training F1 Micro: 0.9294 | Validation F1 Micro : 0.6440
Epoch 7, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 2.2288e-02 | Validation Loss : 2.2985e-02
Training CC : 0.9157 | Validation CC : 0.9109
** Classification Losses **
Training Loss : 4.7860e-01 | Validation Loss : 9.3218e-01
Training F1 Macro: 0.8608 | Validation F1 Macro : 0.6367
Training F1 Micro: 0.9125 | Validation F1 Micro : 0.6400
Epoch 7, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 2.0640e-02 | Validation Loss : 2.2053e-02
Training CC : 0.9219 | Validation CC : 0.9149
** Classification Losses **
Training Loss : 4.6922e-01 | Validation Loss : 9.5766e-01
Training F1 Macro: 0.9025 | Validation F1 Macro : 0.5948
Training F1 Micro: 0.9113 | Validation F1 Micro : 0.6040
Epoch 7, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.9462e-02 | Validation Loss : 2.0969e-02
Training CC : 0.9267 | Validation CC : 0.9191
** Classification Losses **
Training Loss : 4.8103e-01 | Validation Loss : 9.5177e-01
Training F1 Macro: 0.8614 | Validation F1 Macro : 0.6067
Training F1 Micro: 0.8945 | Validation F1 Micro : 0.6160
Epoch 7, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.8389e-02 | Validation Loss : 2.0196e-02
Training CC : 0.9309 | Validation CC : 0.9225
** Classification Losses **
Training Loss : 5.3990e-01 | Validation Loss : 9.8757e-01
Training F1 Macro: 0.8741 | Validation F1 Macro : 0.6020
Training F1 Micro: 0.8875 | Validation F1 Micro : 0.6060
Epoch 8, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.7780e-02 | Validation Loss : 2.0791e-02
Training CC : 0.9331 | Validation CC : 0.9201
** Classification Losses ** <---- Now Optimizing
Training Loss : 4.8074e-01 | Validation Loss : 9.3555e-01
Training F1 Macro: 0.8894 | Validation F1 Macro : 0.6286
Training F1 Micro: 0.8711 | Validation F1 Micro : 0.6280
Epoch 8, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.8955e-02 | Validation Loss : 2.2192e-02
Training CC : 0.9284 | Validation CC : 0.9145
** Classification Losses ** <---- Now Optimizing
Training Loss : 4.1271e-01 | Validation Loss : 9.3977e-01
Training F1 Macro: 0.8991 | Validation F1 Macro : 0.6416
Training F1 Micro: 0.9057 | Validation F1 Micro : 0.6340
Epoch 8, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 2.0248e-02 | Validation Loss : 2.2897e-02
Training CC : 0.9233 | Validation CC : 0.9116
** Classification Losses ** <---- Now Optimizing
Training Loss : 3.6204e-01 | Validation Loss : 9.2149e-01
Training F1 Macro: 0.9219 | Validation F1 Macro : 0.6617
Training F1 Micro: 0.9205 | Validation F1 Micro : 0.6540
Epoch 8, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 2.1133e-02 | Validation Loss : 2.3551e-02
Training CC : 0.9201 | Validation CC : 0.9089
** Classification Losses ** <---- Now Optimizing
Training Loss : 3.3710e-01 | Validation Loss : 9.3359e-01
Training F1 Macro: 0.9039 | Validation F1 Macro : 0.6330
Training F1 Micro: 0.9092 | Validation F1 Micro : 0.6280
Epoch 8, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 2.2090e-02 | Validation Loss : 2.4345e-02
Training CC : 0.9166 | Validation CC : 0.9057
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.3895e-01 | Validation Loss : 9.5366e-01
Training F1 Macro: 0.9673 | Validation F1 Macro : 0.6222
Training F1 Micro: 0.9599 | Validation F1 Micro : 0.6180
Epoch 9, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 2.0796e-02 | Validation Loss : 2.1356e-02
Training CC : 0.9217 | Validation CC : 0.9177
** Classification Losses **
Training Loss : 2.6027e-01 | Validation Loss : 9.2510e-01
Training F1 Macro: 0.9396 | Validation F1 Macro : 0.6262
Training F1 Micro: 0.9318 | Validation F1 Micro : 0.6260
Epoch 9, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.8047e-02 | Validation Loss : 2.0061e-02
Training CC : 0.9319 | Validation CC : 0.9228
** Classification Losses **
Training Loss : 2.2495e-01 | Validation Loss : 9.0182e-01
Training F1 Macro: 0.9634 | Validation F1 Macro : 0.6524
Training F1 Micro: 0.9699 | Validation F1 Micro : 0.6520
Epoch 9, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.6831e-02 | Validation Loss : 1.9079e-02
Training CC : 0.9368 | Validation CC : 0.9269
** Classification Losses **
Training Loss : 2.6530e-01 | Validation Loss : 8.9400e-01
Training F1 Macro: 0.9469 | Validation F1 Macro : 0.6384
Training F1 Micro: 0.9423 | Validation F1 Micro : 0.6420
Epoch 9, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.5871e-02 | Validation Loss : 1.8142e-02
Training CC : 0.9404 | Validation CC : 0.9305
** Classification Losses **
Training Loss : 2.7760e-01 | Validation Loss : 9.0853e-01
Training F1 Macro: 0.9513 | Validation F1 Macro : 0.6179
Training F1 Micro: 0.9489 | Validation F1 Micro : 0.6200
Epoch 9, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.5164e-02 | Validation Loss : 1.7539e-02
Training CC : 0.9436 | Validation CC : 0.9331
** Classification Losses **
Training Loss : 3.1673e-01 | Validation Loss : 9.1956e-01
Training F1 Macro: 0.9232 | Validation F1 Macro : 0.6268
Training F1 Micro: 0.9280 | Validation F1 Micro : 0.6280
Epoch 10, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.4578e-02 | Validation Loss : 1.7977e-02
Training CC : 0.9456 | Validation CC : 0.9313
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.6310e-01 | Validation Loss : 9.4249e-01
Training F1 Macro: 0.9633 | Validation F1 Macro : 0.6326
Training F1 Micro: 0.9600 | Validation F1 Micro : 0.6280
Epoch 10, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.5383e-02 | Validation Loss : 1.8928e-02
Training CC : 0.9423 | Validation CC : 0.9275
** Classification Losses ** <---- Now Optimizing
Training Loss : 3.1046e-01 | Validation Loss : 9.0960e-01
Training F1 Macro: 0.8953 | Validation F1 Macro : 0.6527
Training F1 Micro: 0.9013 | Validation F1 Micro : 0.6480
Epoch 10, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.6955e-02 | Validation Loss : 1.9794e-02
Training CC : 0.9373 | Validation CC : 0.9240
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.8785e-01 | Validation Loss : 9.0399e-01
Training F1 Macro: 0.9519 | Validation F1 Macro : 0.6345
Training F1 Micro: 0.9552 | Validation F1 Micro : 0.6380
Epoch 10, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.7438e-02 | Validation Loss : 2.0332e-02
Training CC : 0.9346 | Validation CC : 0.9218
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.9113e-01 | Validation Loss : 9.2813e-01
Training F1 Macro: 0.9222 | Validation F1 Macro : 0.6069
Training F1 Micro: 0.9236 | Validation F1 Micro : 0.6060
Epoch 10, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.7993e-02 | Validation Loss : 2.0730e-02
Training CC : 0.9326 | Validation CC : 0.9202
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.8799e-01 | Validation Loss : 9.0754e-01
Training F1 Macro: 0.9206 | Validation F1 Macro : 0.6161
Training F1 Micro: 0.9205 | Validation F1 Micro : 0.6220
Epoch 11, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.7403e-02 | Validation Loss : 1.8835e-02
Training CC : 0.9364 | Validation CC : 0.9279
** Classification Losses **
Training Loss : 2.6457e-01 | Validation Loss : 8.8831e-01
Training F1 Macro: 0.8917 | Validation F1 Macro : 0.6314
Training F1 Micro: 0.8893 | Validation F1 Micro : 0.6320
Epoch 11, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.5003e-02 | Validation Loss : 1.7768e-02
Training CC : 0.9438 | Validation CC : 0.9321
** Classification Losses **
Training Loss : 1.8082e-01 | Validation Loss : 8.8316e-01
Training F1 Macro: 0.9293 | Validation F1 Macro : 0.6331
Training F1 Micro: 0.9375 | Validation F1 Micro : 0.6380
Epoch 11, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.4159e-02 | Validation Loss : 1.6959e-02
Training CC : 0.9474 | Validation CC : 0.9354
** Classification Losses **
Training Loss : 2.0158e-01 | Validation Loss : 8.6954e-01
Training F1 Macro: 0.9375 | Validation F1 Macro : 0.6380
Training F1 Micro: 0.9474 | Validation F1 Micro : 0.6460
Epoch 11, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.3952e-02 | Validation Loss : 1.6245e-02
Training CC : 0.9492 | Validation CC : 0.9380
** Classification Losses **
Training Loss : 2.5369e-01 | Validation Loss : 8.8022e-01
Training F1 Macro: 0.8668 | Validation F1 Macro : 0.6351
Training F1 Micro: 0.8916 | Validation F1 Micro : 0.6380
Epoch 11, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.2904e-02 | Validation Loss : 1.5950e-02
Training CC : 0.9524 | Validation CC : 0.9396
** Classification Losses **
Training Loss : 1.8340e-01 | Validation Loss : 8.6461e-01
Training F1 Macro: 0.9492 | Validation F1 Macro : 0.6339
Training F1 Micro: 0.9501 | Validation F1 Micro : 0.6380
Epoch 12, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.2211e-02 | Validation Loss : 1.6111e-02
Training CC : 0.9546 | Validation CC : 0.9390
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.2418e-01 | Validation Loss : 8.9275e-01
Training F1 Macro: 0.8881 | Validation F1 Macro : 0.6358
Training F1 Micro: 0.9305 | Validation F1 Micro : 0.6340
Epoch 12, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.2899e-02 | Validation Loss : 1.6743e-02
Training CC : 0.9522 | Validation CC : 0.9365
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.0333e-01 | Validation Loss : 9.3081e-01
Training F1 Macro: 0.9174 | Validation F1 Macro : 0.6288
Training F1 Micro: 0.9166 | Validation F1 Micro : 0.6240
Epoch 12, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.3326e-02 | Validation Loss : 1.7252e-02
Training CC : 0.9503 | Validation CC : 0.9344
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.8194e-01 | Validation Loss : 8.7050e-01
Training F1 Macro: 0.9065 | Validation F1 Macro : 0.6398
Training F1 Micro: 0.9100 | Validation F1 Micro : 0.6440
Epoch 12, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.4215e-02 | Validation Loss : 1.8197e-02
Training CC : 0.9469 | Validation CC : 0.9307
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.9415e-01 | Validation Loss : 8.7652e-01
Training F1 Macro: 0.9131 | Validation F1 Macro : 0.6182
Training F1 Micro: 0.9005 | Validation F1 Micro : 0.6220
Epoch 12, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.5127e-02 | Validation Loss : 1.8726e-02
Training CC : 0.9434 | Validation CC : 0.9287
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.0680e-01 | Validation Loss : 8.7771e-01
Training F1 Macro: 0.8930 | Validation F1 Macro : 0.6297
Training F1 Micro: 0.9006 | Validation F1 Micro : 0.6300
Epoch 13, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.4305e-02 | Validation Loss : 1.6714e-02
Training CC : 0.9470 | Validation CC : 0.9365
** Classification Losses **
Training Loss : 2.1443e-01 | Validation Loss : 8.6231e-01
Training F1 Macro: 0.8839 | Validation F1 Macro : 0.6399
Training F1 Micro: 0.8928 | Validation F1 Micro : 0.6440
Epoch 13, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.3025e-02 | Validation Loss : 1.5881e-02
Training CC : 0.9522 | Validation CC : 0.9397
** Classification Losses **
Training Loss : 1.7527e-01 | Validation Loss : 8.4568e-01
Training F1 Macro: 0.9115 | Validation F1 Macro : 0.6464
Training F1 Micro: 0.9205 | Validation F1 Micro : 0.6500
Epoch 13, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.2185e-02 | Validation Loss : 1.5217e-02
Training CC : 0.9553 | Validation CC : 0.9422
** Classification Losses **
Training Loss : 1.6836e-01 | Validation Loss : 8.3084e-01
Training F1 Macro: 0.9136 | Validation F1 Macro : 0.6637
Training F1 Micro: 0.9199 | Validation F1 Micro : 0.6680
Epoch 13, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.1708e-02 | Validation Loss : 1.4811e-02
Training CC : 0.9574 | Validation CC : 0.9439
** Classification Losses **
Training Loss : 1.5179e-01 | Validation Loss : 8.5556e-01
Training F1 Macro: 0.9303 | Validation F1 Macro : 0.6488
Training F1 Micro: 0.9267 | Validation F1 Micro : 0.6520
Epoch 13, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.0926e-02 | Validation Loss : 1.4488e-02
Training CC : 0.9596 | Validation CC : 0.9454
** Classification Losses **
Training Loss : 1.6101e-01 | Validation Loss : 8.4275e-01
Training F1 Macro: 0.9315 | Validation F1 Macro : 0.6548
Training F1 Micro: 0.9523 | Validation F1 Micro : 0.6600
Epoch 14, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.0402e-02 | Validation Loss : 1.4740e-02
Training CC : 0.9614 | Validation CC : 0.9444
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.7058e-01 | Validation Loss : 8.3775e-01
Training F1 Macro: 0.9381 | Validation F1 Macro : 0.6698
Training F1 Micro: 0.9402 | Validation F1 Micro : 0.6740
Epoch 14, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.1162e-02 | Validation Loss : 1.5246e-02
Training CC : 0.9591 | Validation CC : 0.9424
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.9570e-01 | Validation Loss : 8.7155e-01
Training F1 Macro: 0.8464 | Validation F1 Macro : 0.6625
Training F1 Micro: 0.9012 | Validation F1 Micro : 0.6660
Epoch 14, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.1356e-02 | Validation Loss : 1.5513e-02
Training CC : 0.9579 | Validation CC : 0.9413
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.8357e-01 | Validation Loss : 8.6651e-01
Training F1 Macro: 0.9284 | Validation F1 Macro : 0.6500
Training F1 Micro: 0.9274 | Validation F1 Micro : 0.6540
Epoch 14, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.1680e-02 | Validation Loss : 1.5805e-02
Training CC : 0.9568 | Validation CC : 0.9401
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.9267e-01 | Validation Loss : 8.7959e-01
Training F1 Macro: 0.9022 | Validation F1 Macro : 0.6232
Training F1 Micro: 0.9061 | Validation F1 Micro : 0.6280
Epoch 14, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 1.1952e-02 | Validation Loss : 1.6067e-02
Training CC : 0.9556 | Validation CC : 0.9391
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.1783e-01 | Validation Loss : 8.5367e-01
Training F1 Macro: 0.9383 | Validation F1 Macro : 0.6733
Training F1 Micro: 0.9424 | Validation F1 Micro : 0.6780
Epoch 15, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.1371e-02 | Validation Loss : 1.5021e-02
Training CC : 0.9578 | Validation CC : 0.9432
** Classification Losses **
Training Loss : 2.6352e-01 | Validation Loss : 8.3245e-01
Training F1 Macro: 0.8697 | Validation F1 Macro : 0.6602
Training F1 Micro: 0.8753 | Validation F1 Micro : 0.6640
Epoch 15, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.0914e-02 | Validation Loss : 1.4526e-02
Training CC : 0.9600 | Validation CC : 0.9452
** Classification Losses **
Training Loss : 1.6287e-01 | Validation Loss : 8.3996e-01
Training F1 Macro: 0.9177 | Validation F1 Macro : 0.6691
Training F1 Micro: 0.9348 | Validation F1 Micro : 0.6720
Epoch 15, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 1.0366e-02 | Validation Loss : 1.4301e-02
Training CC : 0.9622 | Validation CC : 0.9460
** Classification Losses **
Training Loss : 1.4815e-01 | Validation Loss : 8.3877e-01
Training F1 Macro: 0.9482 | Validation F1 Macro : 0.6721
Training F1 Micro: 0.9478 | Validation F1 Micro : 0.6740
Epoch 15, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 9.8331e-03 | Validation Loss : 1.3929e-02
Training CC : 0.9638 | Validation CC : 0.9474
** Classification Losses **
Training Loss : 9.2873e-02 | Validation Loss : 8.5900e-01
Training F1 Macro: 0.9573 | Validation F1 Macro : 0.6487
Training F1 Micro: 0.9590 | Validation F1 Micro : 0.6540
Epoch 15, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 9.3855e-03 | Validation Loss : 1.3776e-02
Training CC : 0.9654 | Validation CC : 0.9482
** Classification Losses **
Training Loss : 1.3484e-01 | Validation Loss : 8.4049e-01
Training F1 Macro: 0.9553 | Validation F1 Macro : 0.6748
Training F1 Micro: 0.9591 | Validation F1 Micro : 0.6760
Epoch 16, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 9.3653e-03 | Validation Loss : 1.3777e-02
Training CC : 0.9657 | Validation CC : 0.9482
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.3203e-01 | Validation Loss : 8.4416e-01
Training F1 Macro: 0.9486 | Validation F1 Macro : 0.6665
Training F1 Micro: 0.9518 | Validation F1 Micro : 0.6680
Epoch 16, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 9.3063e-03 | Validation Loss : 1.3871e-02
Training CC : 0.9657 | Validation CC : 0.9479
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.8428e-01 | Validation Loss : 8.5315e-01
Training F1 Macro: 0.9073 | Validation F1 Macro : 0.6563
Training F1 Micro: 0.9105 | Validation F1 Micro : 0.6580
Epoch 16, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 9.3482e-03 | Validation Loss : 1.4009e-02
Training CC : 0.9654 | Validation CC : 0.9473
** Classification Losses ** <---- Now Optimizing
Training Loss : 9.9010e-02 | Validation Loss : 8.7678e-01
Training F1 Macro: 0.9536 | Validation F1 Macro : 0.6413
Training F1 Micro: 0.9542 | Validation F1 Micro : 0.6440
Epoch 16, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 9.6327e-03 | Validation Loss : 1.4144e-02
Training CC : 0.9645 | Validation CC : 0.9468
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.2682e-01 | Validation Loss : 9.0067e-01
Training F1 Macro: 0.9485 | Validation F1 Macro : 0.6325
Training F1 Micro: 0.9587 | Validation F1 Micro : 0.6340
Epoch 16, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 9.7647e-03 | Validation Loss : 1.4251e-02
Training CC : 0.9640 | Validation CC : 0.9463
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.0845e-01 | Validation Loss : 8.6177e-01
Training F1 Macro: 0.9578 | Validation F1 Macro : 0.6502
Training F1 Micro: 0.9454 | Validation F1 Micro : 0.6540
Epoch 17, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 9.4497e-03 | Validation Loss : 1.3772e-02
Training CC : 0.9650 | Validation CC : 0.9481
** Classification Losses **
Training Loss : 1.6202e-01 | Validation Loss : 8.5356e-01
Training F1 Macro: 0.8868 | Validation F1 Macro : 0.6650
Training F1 Micro: 0.8992 | Validation F1 Micro : 0.6680
Epoch 17, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 9.2654e-03 | Validation Loss : 1.3456e-02
Training CC : 0.9662 | Validation CC : 0.9493
** Classification Losses **
Training Loss : 2.0396e-01 | Validation Loss : 8.3408e-01
Training F1 Macro: 0.9091 | Validation F1 Macro : 0.6467
Training F1 Micro: 0.9120 | Validation F1 Micro : 0.6500
Epoch 17, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 8.9745e-03 | Validation Loss : 1.3355e-02
Training CC : 0.9672 | Validation CC : 0.9497
** Classification Losses **
Training Loss : 1.3781e-01 | Validation Loss : 8.6047e-01
Training F1 Macro: 0.9214 | Validation F1 Macro : 0.6386
Training F1 Micro: 0.9383 | Validation F1 Micro : 0.6440
Epoch 17, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 8.8195e-03 | Validation Loss : 1.3154e-02
Training CC : 0.9679 | Validation CC : 0.9506
** Classification Losses **
Training Loss : 1.9023e-01 | Validation Loss : 8.4928e-01
Training F1 Macro: 0.8888 | Validation F1 Macro : 0.6667
Training F1 Micro: 0.9071 | Validation F1 Micro : 0.6680
Epoch 17, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 8.6157e-03 | Validation Loss : 1.3201e-02
Training CC : 0.9687 | Validation CC : 0.9505
** Classification Losses **
Training Loss : 1.4719e-01 | Validation Loss : 8.4225e-01
Training F1 Macro: 0.9113 | Validation F1 Macro : 0.6757
Training F1 Micro: 0.9200 | Validation F1 Micro : 0.6780
Epoch 18, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 8.3774e-03 | Validation Loss : 1.3181e-02
Training CC : 0.9693 | Validation CC : 0.9505
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.5271e-01 | Validation Loss : 8.3087e-01
Training F1 Macro: 0.9156 | Validation F1 Macro : 0.6696
Training F1 Micro: 0.9216 | Validation F1 Micro : 0.6720
Epoch 18, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 8.4135e-03 | Validation Loss : 1.3251e-02
Training CC : 0.9692 | Validation CC : 0.9503
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.7403e-01 | Validation Loss : 8.7227e-01
Training F1 Macro: 0.9213 | Validation F1 Macro : 0.6358
Training F1 Micro: 0.9188 | Validation F1 Micro : 0.6420
Epoch 18, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 8.5600e-03 | Validation Loss : 1.3404e-02
Training CC : 0.9687 | Validation CC : 0.9496
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.7112e-01 | Validation Loss : 8.8280e-01
Training F1 Macro: 0.9297 | Validation F1 Macro : 0.6452
Training F1 Micro: 0.9209 | Validation F1 Micro : 0.6460
Epoch 18, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 9.1894e-03 | Validation Loss : 1.3514e-02
Training CC : 0.9672 | Validation CC : 0.9492
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.0314e-01 | Validation Loss : 8.9198e-01
Training F1 Macro: 0.9431 | Validation F1 Macro : 0.6361
Training F1 Micro: 0.9462 | Validation F1 Micro : 0.6360
Epoch 18, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 8.7022e-03 | Validation Loss : 1.3546e-02
Training CC : 0.9680 | Validation CC : 0.9491
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.5245e-01 | Validation Loss : 8.7273e-01
Training F1 Macro: 0.9139 | Validation F1 Macro : 0.6438
Training F1 Micro: 0.9120 | Validation F1 Micro : 0.6460
Epoch 19, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 9.6351e-03 | Validation Loss : 1.3262e-02
Training CC : 0.9662 | Validation CC : 0.9502
** Classification Losses **
Training Loss : 1.4997e-01 | Validation Loss : 8.7745e-01
Training F1 Macro: 0.8983 | Validation F1 Macro : 0.6264
Training F1 Micro: 0.9022 | Validation F1 Micro : 0.6260
Epoch 19, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 8.8020e-03 | Validation Loss : 1.2972e-02
Training CC : 0.9688 | Validation CC : 0.9513
** Classification Losses **
Training Loss : 1.2232e-01 | Validation Loss : 8.5785e-01
Training F1 Macro: 0.9535 | Validation F1 Macro : 0.6637
Training F1 Micro: 0.9592 | Validation F1 Micro : 0.6680
Epoch 19, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 9.5769e-03 | Validation Loss : 1.2744e-02
Training CC : 0.9670 | Validation CC : 0.9524
** Classification Losses **
Training Loss : 1.3234e-01 | Validation Loss : 8.5989e-01
Training F1 Macro: 0.9310 | Validation F1 Macro : 0.6593
Training F1 Micro: 0.9431 | Validation F1 Micro : 0.6600
Epoch 19, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 7.9503e-03 | Validation Loss : 1.2637e-02
Training CC : 0.9710 | Validation CC : 0.9524
** Classification Losses **
Training Loss : 1.4379e-01 | Validation Loss : 8.5471e-01
Training F1 Macro: 0.9125 | Validation F1 Macro : 0.6611
Training F1 Micro: 0.9323 | Validation F1 Micro : 0.6620
Epoch 19, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 7.7567e-03 | Validation Loss : 1.2581e-02
Training CC : 0.9718 | Validation CC : 0.9532
** Classification Losses **
Training Loss : 1.3960e-01 | Validation Loss : 8.4192e-01
Training F1 Macro: 0.9126 | Validation F1 Macro : 0.6726
Training F1 Micro: 0.9318 | Validation F1 Micro : 0.6800
Epoch 20, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 7.4657e-03 | Validation Loss : 1.2658e-02
Training CC : 0.9726 | Validation CC : 0.9530
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.5172e-01 | Validation Loss : 8.6882e-01
Training F1 Macro: 0.9454 | Validation F1 Macro : 0.6556
Training F1 Micro: 0.9467 | Validation F1 Micro : 0.6560
Epoch 20, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 7.8149e-03 | Validation Loss : 1.2747e-02
Training CC : 0.9718 | Validation CC : 0.9526
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.2112e-01 | Validation Loss : 8.6369e-01
Training F1 Macro: 0.9362 | Validation F1 Macro : 0.6560
Training F1 Micro: 0.9397 | Validation F1 Micro : 0.6580
Epoch 20, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 7.7463e-03 | Validation Loss : 1.2798e-02
Training CC : 0.9718 | Validation CC : 0.9524
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.5293e-01 | Validation Loss : 8.5455e-01
Training F1 Macro: 0.9039 | Validation F1 Macro : 0.6618
Training F1 Micro: 0.9158 | Validation F1 Micro : 0.6640
Epoch 20, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 7.7043e-03 | Validation Loss : 1.2875e-02
Training CC : 0.9717 | Validation CC : 0.9521
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.6206e-01 | Validation Loss : 8.4736e-01
Training F1 Macro: 0.9281 | Validation F1 Macro : 0.6759
Training F1 Micro: 0.9342 | Validation F1 Micro : 0.6760
Epoch 20, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 8.2563e-03 | Validation Loss : 1.2997e-02
Training CC : 0.9705 | Validation CC : 0.9516
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.7141e-01 | Validation Loss : 8.5383e-01
Training F1 Macro: 0.9108 | Validation F1 Macro : 0.6694
Training F1 Micro: 0.9116 | Validation F1 Micro : 0.6700
Epoch 21, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 7.7102e-03 | Validation Loss : 1.2534e-02
Training CC : 0.9718 | Validation CC : 0.9529
** Classification Losses **
Training Loss : 1.6567e-01 | Validation Loss : 8.6571e-01
Training F1 Macro: 0.8981 | Validation F1 Macro : 0.6701
Training F1 Micro: 0.9118 | Validation F1 Micro : 0.6700
Epoch 21, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 7.2278e-03 | Validation Loss : 1.2528e-02
Training CC : 0.9734 | Validation CC : 0.9532
** Classification Losses **
Training Loss : 9.3937e-02 | Validation Loss : 8.4098e-01
Training F1 Macro: 0.9457 | Validation F1 Macro : 0.6727
Training F1 Micro: 0.9493 | Validation F1 Micro : 0.6760
Epoch 21, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 7.1630e-03 | Validation Loss : 1.2346e-02
Training CC : 0.9739 | Validation CC : 0.9541
** Classification Losses **
Training Loss : 1.0077e-01 | Validation Loss : 8.4972e-01
Training F1 Macro: 0.8803 | Validation F1 Macro : 0.6569
Training F1 Micro: 0.9387 | Validation F1 Micro : 0.6620
Epoch 21, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 7.8948e-03 | Validation Loss : 1.2502e-02
Training CC : 0.9726 | Validation CC : 0.9537
** Classification Losses **
Training Loss : 1.9061e-01 | Validation Loss : 8.4001e-01
Training F1 Macro: 0.9014 | Validation F1 Macro : 0.6726
Training F1 Micro: 0.9081 | Validation F1 Micro : 0.6760
Epoch 21, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 7.2557e-03 | Validation Loss : 1.2409e-02
Training CC : 0.9739 | Validation CC : 0.9534
** Classification Losses **
Training Loss : 1.6901e-01 | Validation Loss : 8.6209e-01
Training F1 Macro: 0.9469 | Validation F1 Macro : 0.6626
Training F1 Micro: 0.9406 | Validation F1 Micro : 0.6640
Epoch 22, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 7.2670e-03 | Validation Loss : 1.2509e-02
Training CC : 0.9736 | Validation CC : 0.9530
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.3909e-01 | Validation Loss : 8.3192e-01
Training F1 Macro: 0.8593 | Validation F1 Macro : 0.6702
Training F1 Micro: 0.8630 | Validation F1 Micro : 0.6720
Epoch 22, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 7.9881e-03 | Validation Loss : 1.2611e-02
Training CC : 0.9720 | Validation CC : 0.9526
** Classification Losses ** <---- Now Optimizing
Training Loss : 9.9960e-02 | Validation Loss : 8.4697e-01
Training F1 Macro: 0.9484 | Validation F1 Macro : 0.6510
Training F1 Micro: 0.9462 | Validation F1 Micro : 0.6560
Epoch 22, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 7.2603e-03 | Validation Loss : 1.2619e-02
Training CC : 0.9734 | Validation CC : 0.9526
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.0235e-01 | Validation Loss : 8.7750e-01
Training F1 Macro: 0.9672 | Validation F1 Macro : 0.6185
Training F1 Micro: 0.9737 | Validation F1 Micro : 0.6160
Epoch 22, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 7.4607e-03 | Validation Loss : 1.2630e-02
Training CC : 0.9730 | Validation CC : 0.9525
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.3184e-01 | Validation Loss : 8.5133e-01
Training F1 Macro: 0.9854 | Validation F1 Macro : 0.6330
Training F1 Micro: 0.9831 | Validation F1 Micro : 0.6360
Epoch 22, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 7.2900e-03 | Validation Loss : 1.2654e-02
Training CC : 0.9733 | Validation CC : 0.9524
** Classification Losses ** <---- Now Optimizing
Training Loss : 9.0637e-02 | Validation Loss : 8.5801e-01
Training F1 Macro: 0.9771 | Validation F1 Macro : 0.6579
Training F1 Micro: 0.9715 | Validation F1 Micro : 0.6640
Epoch 23, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 7.4450e-03 | Validation Loss : 1.2751e-02
Training CC : 0.9733 | Validation CC : 0.9533
** Classification Losses **
Training Loss : 1.0397e-01 | Validation Loss : 8.5559e-01
Training F1 Macro: 0.9489 | Validation F1 Macro : 0.6641
Training F1 Micro: 0.9584 | Validation F1 Micro : 0.6660
Epoch 23, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 7.9086e-03 | Validation Loss : 1.2338e-02
Training CC : 0.9726 | Validation CC : 0.9536
** Classification Losses **
Training Loss : 1.5325e-01 | Validation Loss : 8.3072e-01
Training F1 Macro: 0.9345 | Validation F1 Macro : 0.6725
Training F1 Micro: 0.9393 | Validation F1 Micro : 0.6720
Epoch 23, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.9315e-03 | Validation Loss : 1.2355e-02
Training CC : 0.9745 | Validation CC : 0.9542
** Classification Losses **
Training Loss : 8.7520e-02 | Validation Loss : 8.5744e-01
Training F1 Macro: 0.9515 | Validation F1 Macro : 0.6702
Training F1 Micro: 0.9689 | Validation F1 Micro : 0.6700
Epoch 23, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.6386e-03 | Validation Loss : 1.1937e-02
Training CC : 0.9755 | Validation CC : 0.9556
** Classification Losses **
Training Loss : 2.3212e-01 | Validation Loss : 8.3361e-01
Training F1 Macro: 0.8921 | Validation F1 Macro : 0.6773
Training F1 Micro: 0.8836 | Validation F1 Micro : 0.6800
Epoch 23, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.8403e-03 | Validation Loss : 1.1840e-02
Training CC : 0.9755 | Validation CC : 0.9557
** Classification Losses **
Training Loss : 1.4800e-01 | Validation Loss : 8.3969e-01
Training F1 Macro: 0.9263 | Validation F1 Macro : 0.6680
Training F1 Micro: 0.9285 | Validation F1 Micro : 0.6720
Epoch 24, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 6.3760e-03 | Validation Loss : 1.1916e-02
Training CC : 0.9767 | Validation CC : 0.9554
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.9337e-01 | Validation Loss : 8.5417e-01
Training F1 Macro: 0.8829 | Validation F1 Macro : 0.6304
Training F1 Micro: 0.8798 | Validation F1 Micro : 0.6320
Epoch 24, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 6.8312e-03 | Validation Loss : 1.2025e-02
Training CC : 0.9756 | Validation CC : 0.9549
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.3159e-01 | Validation Loss : 8.4960e-01
Training F1 Macro: 0.9314 | Validation F1 Macro : 0.6426
Training F1 Micro: 0.9403 | Validation F1 Micro : 0.6440
Epoch 24, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 6.6599e-03 | Validation Loss : 1.2106e-02
Training CC : 0.9757 | Validation CC : 0.9546
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.2548e-01 | Validation Loss : 8.6852e-01
Training F1 Macro: 0.9326 | Validation F1 Macro : 0.6410
Training F1 Micro: 0.9348 | Validation F1 Micro : 0.6400
Epoch 24, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 7.0657e-03 | Validation Loss : 1.2199e-02
Training CC : 0.9748 | Validation CC : 0.9543
** Classification Losses ** <---- Now Optimizing
Training Loss : 8.6306e-02 | Validation Loss : 8.7201e-01
Training F1 Macro: 0.9516 | Validation F1 Macro : 0.6488
Training F1 Micro: 0.9573 | Validation F1 Micro : 0.6500
Epoch 24, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 6.9443e-03 | Validation Loss : 1.2281e-02
Training CC : 0.9748 | Validation CC : 0.9539
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.5603e-01 | Validation Loss : 8.5981e-01
Training F1 Macro: 0.8968 | Validation F1 Macro : 0.6425
Training F1 Micro: 0.9048 | Validation F1 Micro : 0.6460
Epoch 25, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.7960e-03 | Validation Loss : 1.1807e-02
Training CC : 0.9755 | Validation CC : 0.9558
** Classification Losses **
Training Loss : 1.8760e-01 | Validation Loss : 8.3187e-01
Training F1 Macro: 0.9100 | Validation F1 Macro : 0.6752
Training F1 Micro: 0.9080 | Validation F1 Micro : 0.6780
Epoch 25, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.2898e-03 | Validation Loss : 1.1782e-02
Training CC : 0.9770 | Validation CC : 0.9563
** Classification Losses **
Training Loss : 1.7058e-01 | Validation Loss : 8.4101e-01
Training F1 Macro: 0.9096 | Validation F1 Macro : 0.6540
Training F1 Micro: 0.9099 | Validation F1 Micro : 0.6560
Epoch 25, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.2050e-03 | Validation Loss : 1.1777e-02
Training CC : 0.9775 | Validation CC : 0.9561
** Classification Losses **
Training Loss : 1.3243e-01 | Validation Loss : 8.4678e-01
Training F1 Macro: 0.9281 | Validation F1 Macro : 0.6581
Training F1 Micro: 0.9244 | Validation F1 Micro : 0.6620
Epoch 25, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.2643e-03 | Validation Loss : 1.1752e-02
Training CC : 0.9775 | Validation CC : 0.9563
** Classification Losses **
Training Loss : 1.6075e-01 | Validation Loss : 8.5280e-01
Training F1 Macro: 0.8845 | Validation F1 Macro : 0.6536
Training F1 Micro: 0.9310 | Validation F1 Micro : 0.6580
Epoch 25, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 7.6090e-03 | Validation Loss : 1.1833e-02
Training CC : 0.9741 | Validation CC : 0.9565
** Classification Losses **
Training Loss : 1.7908e-01 | Validation Loss : 8.3545e-01
Training F1 Macro: 0.9072 | Validation F1 Macro : 0.6727
Training F1 Micro: 0.9045 | Validation F1 Micro : 0.6740
Epoch 26, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 6.5355e-03 | Validation Loss : 1.1902e-02
Training CC : 0.9769 | Validation CC : 0.9562
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.3773e-01 | Validation Loss : 8.6412e-01
Training F1 Macro: 0.9130 | Validation F1 Macro : 0.6296
Training F1 Micro: 0.9073 | Validation F1 Micro : 0.6260
Epoch 26, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 6.6034e-03 | Validation Loss : 1.2097e-02
Training CC : 0.9767 | Validation CC : 0.9555
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.8693e-01 | Validation Loss : 8.2975e-01
Training F1 Macro: 0.8809 | Validation F1 Macro : 0.6717
Training F1 Micro: 0.9176 | Validation F1 Micro : 0.6760
Epoch 26, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 6.9234e-03 | Validation Loss : 1.2210e-02
Training CC : 0.9757 | Validation CC : 0.9551
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.3756e-01 | Validation Loss : 8.4827e-01
Training F1 Macro: 0.9289 | Validation F1 Macro : 0.6630
Training F1 Micro: 0.9199 | Validation F1 Micro : 0.6680
Epoch 26, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 6.7050e-03 | Validation Loss : 1.2251e-02
Training CC : 0.9759 | Validation CC : 0.9549
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.0720e-01 | Validation Loss : 8.4041e-01
Training F1 Macro: 0.9053 | Validation F1 Macro : 0.6773
Training F1 Micro: 0.9407 | Validation F1 Micro : 0.6780
Epoch 26, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 6.9454e-03 | Validation Loss : 1.2291e-02
Training CC : 0.9754 | Validation CC : 0.9548
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.0907e-01 | Validation Loss : 8.7245e-01
Training F1 Macro: 0.8698 | Validation F1 Macro : 0.6428
Training F1 Micro: 0.8692 | Validation F1 Micro : 0.6420
Epoch 27, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.5478e-03 | Validation Loss : 1.1961e-02
Training CC : 0.9762 | Validation CC : 0.9550
** Classification Losses **
Training Loss : 1.7095e-01 | Validation Loss : 8.2854e-01
Training F1 Macro: 0.8678 | Validation F1 Macro : 0.6808
Training F1 Micro: 0.9182 | Validation F1 Micro : 0.6840
Epoch 27, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.6915e-03 | Validation Loss : 1.2062e-02
Training CC : 0.9763 | Validation CC : 0.9557
** Classification Losses **
Training Loss : 1.8538e-01 | Validation Loss : 8.0424e-01
Training F1 Macro: 0.9061 | Validation F1 Macro : 0.6884
Training F1 Micro: 0.9211 | Validation F1 Micro : 0.6920
Epoch 27, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.1259e-03 | Validation Loss : 1.1760e-02
Training CC : 0.9776 | Validation CC : 0.9561
** Classification Losses **
Training Loss : 1.6386e-01 | Validation Loss : 8.1270e-01
Training F1 Macro: 0.9253 | Validation F1 Macro : 0.6897
Training F1 Micro: 0.9241 | Validation F1 Micro : 0.6900
Epoch 27, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.9430e-03 | Validation Loss : 1.1558e-02
Training CC : 0.9784 | Validation CC : 0.9572
** Classification Losses **
Training Loss : 1.1993e-01 | Validation Loss : 8.1793e-01
Training F1 Macro: 0.9353 | Validation F1 Macro : 0.6836
Training F1 Micro: 0.9362 | Validation F1 Micro : 0.6860
Epoch 27, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.6655e-03 | Validation Loss : 1.1323e-02
Training CC : 0.9791 | Validation CC : 0.9578
** Classification Losses **
Training Loss : 1.8439e-01 | Validation Loss : 8.0809e-01
Training F1 Macro: 0.8148 | Validation F1 Macro : 0.6776
Training F1 Micro: 0.8995 | Validation F1 Micro : 0.6780
Epoch 28, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.7710e-03 | Validation Loss : 1.1375e-02
Training CC : 0.9793 | Validation CC : 0.9576
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.6920e-01 | Validation Loss : 8.1023e-01
Training F1 Macro: 0.9095 | Validation F1 Macro : 0.6824
Training F1 Micro: 0.9059 | Validation F1 Micro : 0.6820
Epoch 28, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.6112e-03 | Validation Loss : 1.1456e-02
Training CC : 0.9795 | Validation CC : 0.9573
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.8149e-01 | Validation Loss : 8.0933e-01
Training F1 Macro: 0.9325 | Validation F1 Macro : 0.6672
Training F1 Micro: 0.9297 | Validation F1 Micro : 0.6660
Epoch 28, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.7544e-03 | Validation Loss : 1.1528e-02
Training CC : 0.9791 | Validation CC : 0.9570
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.6036e-01 | Validation Loss : 8.2073e-01
Training F1 Macro: 0.9014 | Validation F1 Macro : 0.6646
Training F1 Micro: 0.9183 | Validation F1 Micro : 0.6640
Epoch 28, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.7814e-03 | Validation Loss : 1.1598e-02
Training CC : 0.9789 | Validation CC : 0.9568
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.7690e-01 | Validation Loss : 8.3923e-01
Training F1 Macro: 0.9221 | Validation F1 Macro : 0.6722
Training F1 Micro: 0.9181 | Validation F1 Micro : 0.6720
Epoch 28, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 6.0055e-03 | Validation Loss : 1.1664e-02
Training CC : 0.9784 | Validation CC : 0.9565
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.1044e-01 | Validation Loss : 8.5828e-01
Training F1 Macro: 0.9339 | Validation F1 Macro : 0.6266
Training F1 Micro: 0.9365 | Validation F1 Micro : 0.6260
Epoch 29, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.0260e-03 | Validation Loss : 1.1496e-02
Training CC : 0.9786 | Validation CC : 0.9571
** Classification Losses **
Training Loss : 2.1454e-01 | Validation Loss : 8.4726e-01
Training F1 Macro: 0.8673 | Validation F1 Macro : 0.6535
Training F1 Micro: 0.8693 | Validation F1 Micro : 0.6520
Epoch 29, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.7346e-03 | Validation Loss : 1.1429e-02
Training CC : 0.9793 | Validation CC : 0.9577
** Classification Losses **
Training Loss : 1.9326e-01 | Validation Loss : 8.1522e-01
Training F1 Macro: 0.8950 | Validation F1 Macro : 0.6816
Training F1 Micro: 0.8892 | Validation F1 Micro : 0.6820
Epoch 29, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.6571e-03 | Validation Loss : 1.1586e-02
Training CC : 0.9776 | Validation CC : 0.9571
** Classification Losses **
Training Loss : 1.5835e-01 | Validation Loss : 8.4449e-01
Training F1 Macro: 0.9246 | Validation F1 Macro : 0.6684
Training F1 Micro: 0.9187 | Validation F1 Micro : 0.6680
Epoch 29, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.0160e-03 | Validation Loss : 1.1712e-02
Training CC : 0.9786 | Validation CC : 0.9570
** Classification Losses **
Training Loss : 1.3173e-01 | Validation Loss : 8.4895e-01
Training F1 Macro: 0.9461 | Validation F1 Macro : 0.6545
Training F1 Micro: 0.9376 | Validation F1 Micro : 0.6540
Epoch 29, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.0046e-03 | Validation Loss : 1.1446e-02
Training CC : 0.9786 | Validation CC : 0.9573
** Classification Losses **
Training Loss : 2.1249e-01 | Validation Loss : 8.2564e-01
Training F1 Macro: 0.8971 | Validation F1 Macro : 0.6800
Training F1 Micro: 0.8965 | Validation F1 Micro : 0.6800
Epoch 30, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.5131e-03 | Validation Loss : 1.1506e-02
Training CC : 0.9798 | Validation CC : 0.9571
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.1722e-01 | Validation Loss : 8.5023e-01
Training F1 Macro: 0.9470 | Validation F1 Macro : 0.6554
Training F1 Micro: 0.9469 | Validation F1 Micro : 0.6560
Epoch 30, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 6.1789e-03 | Validation Loss : 1.1620e-02
Training CC : 0.9784 | Validation CC : 0.9566
** Classification Losses ** <---- Now Optimizing
Training Loss : 9.3728e-02 | Validation Loss : 8.6545e-01
Training F1 Macro: 0.9165 | Validation F1 Macro : 0.6456
Training F1 Micro: 0.9627 | Validation F1 Micro : 0.6460
Epoch 30, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.9624e-03 | Validation Loss : 1.1678e-02
Training CC : 0.9787 | Validation CC : 0.9564
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.3745e-01 | Validation Loss : 8.4971e-01
Training F1 Macro: 0.9098 | Validation F1 Macro : 0.6606
Training F1 Micro: 0.9183 | Validation F1 Micro : 0.6580
Epoch 30, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.7588e-03 | Validation Loss : 1.1750e-02
Training CC : 0.9790 | Validation CC : 0.9561
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.2439e-01 | Validation Loss : 8.3425e-01
Training F1 Macro: 0.9499 | Validation F1 Macro : 0.6723
Training F1 Micro: 0.9469 | Validation F1 Micro : 0.6720
Epoch 30, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 6.0904e-03 | Validation Loss : 1.1768e-02
Training CC : 0.9783 | Validation CC : 0.9560
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.5059e-01 | Validation Loss : 8.3959e-01
Training F1 Macro: 0.9306 | Validation F1 Macro : 0.6670
Training F1 Micro: 0.9508 | Validation F1 Micro : 0.6680
Epoch 31, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.8120e-03 | Validation Loss : 1.1515e-02
Training CC : 0.9789 | Validation CC : 0.9570
** Classification Losses **
Training Loss : 1.4424e-01 | Validation Loss : 8.4361e-01
Training F1 Macro: 0.9326 | Validation F1 Macro : 0.6708
Training F1 Micro: 0.9301 | Validation F1 Micro : 0.6700
Epoch 31, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.6793e-03 | Validation Loss : 1.1356e-02
Training CC : 0.9798 | Validation CC : 0.9579
** Classification Losses **
Training Loss : 1.1209e-01 | Validation Loss : 8.2991e-01
Training F1 Macro: 0.9419 | Validation F1 Macro : 0.6449
Training F1 Micro: 0.9523 | Validation F1 Micro : 0.6460
Epoch 31, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.6743e-03 | Validation Loss : 1.1059e-02
Training CC : 0.9799 | Validation CC : 0.9589
** Classification Losses **
Training Loss : 1.5746e-01 | Validation Loss : 8.3515e-01
Training F1 Macro: 0.9225 | Validation F1 Macro : 0.6828
Training F1 Micro: 0.9186 | Validation F1 Micro : 0.6840
Epoch 31, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.2405e-03 | Validation Loss : 1.0944e-02
Training CC : 0.9792 | Validation CC : 0.9588
** Classification Losses **
Training Loss : 1.5113e-01 | Validation Loss : 8.4694e-01
Training F1 Macro: 0.9277 | Validation F1 Macro : 0.6555
Training F1 Micro: 0.9297 | Validation F1 Micro : 0.6540
Epoch 31, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 6.0254e-03 | Validation Loss : 1.1388e-02
Training CC : 0.9794 | Validation CC : 0.9580
** Classification Losses **
Training Loss : 1.9788e-01 | Validation Loss : 8.5736e-01
Training F1 Macro: 0.9060 | Validation F1 Macro : 0.6525
Training F1 Micro: 0.9128 | Validation F1 Micro : 0.6520
Epoch 32, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.3601e-03 | Validation Loss : 1.1427e-02
Training CC : 0.9805 | Validation CC : 0.9579
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.0559e-01 | Validation Loss : 8.6597e-01
Training F1 Macro: 0.9198 | Validation F1 Macro : 0.6267
Training F1 Micro: 0.9187 | Validation F1 Micro : 0.6280
Epoch 32, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.3356e-03 | Validation Loss : 1.1508e-02
Training CC : 0.9805 | Validation CC : 0.9575
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.9381e-01 | Validation Loss : 8.4151e-01
Training F1 Macro: 0.8839 | Validation F1 Macro : 0.6377
Training F1 Micro: 0.8894 | Validation F1 Micro : 0.6400
Epoch 32, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.9008e-03 | Validation Loss : 1.1651e-02
Training CC : 0.9792 | Validation CC : 0.9570
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.9346e-01 | Validation Loss : 8.5622e-01
Training F1 Macro: 0.8791 | Validation F1 Macro : 0.6252
Training F1 Micro: 0.8857 | Validation F1 Micro : 0.6220
Epoch 32, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.8426e-03 | Validation Loss : 1.1760e-02
Training CC : 0.9791 | Validation CC : 0.9566
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.2083e-01 | Validation Loss : 8.5743e-01
Training F1 Macro: 0.7958 | Validation F1 Macro : 0.6458
Training F1 Micro: 0.8593 | Validation F1 Micro : 0.6420
Epoch 32, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.9243e-03 | Validation Loss : 1.1847e-02
Training CC : 0.9788 | Validation CC : 0.9563
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.2096e-01 | Validation Loss : 8.5580e-01
Training F1 Macro: 0.9475 | Validation F1 Macro : 0.6600
Training F1 Micro: 0.9429 | Validation F1 Micro : 0.6580
Epoch 33, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.7308e-03 | Validation Loss : 1.1139e-02
Training CC : 0.9793 | Validation CC : 0.9585
** Classification Losses **
Training Loss : 1.0056e-01 | Validation Loss : 8.3411e-01
Training F1 Macro: 0.9457 | Validation F1 Macro : 0.6534
Training F1 Micro: 0.9511 | Validation F1 Micro : 0.6520
Epoch 33, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.7654e-03 | Validation Loss : 1.1488e-02
Training CC : 0.9800 | Validation CC : 0.9570
** Classification Losses **
Training Loss : 1.5000e-01 | Validation Loss : 8.2819e-01
Training F1 Macro: 0.9227 | Validation F1 Macro : 0.6874
Training F1 Micro: 0.9258 | Validation F1 Micro : 0.6880
Epoch 33, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.6835e-03 | Validation Loss : 1.1422e-02
Training CC : 0.9799 | Validation CC : 0.9585
** Classification Losses **
Training Loss : 1.1001e-01 | Validation Loss : 8.2048e-01
Training F1 Macro: 0.9374 | Validation F1 Macro : 0.6890
Training F1 Micro: 0.9436 | Validation F1 Micro : 0.6900
Epoch 33, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.4570e-03 | Validation Loss : 1.1138e-02
Training CC : 0.9805 | Validation CC : 0.9585
** Classification Losses **
Training Loss : 1.2294e-01 | Validation Loss : 8.4083e-01
Training F1 Macro: 0.9223 | Validation F1 Macro : 0.6706
Training F1 Micro: 0.9249 | Validation F1 Micro : 0.6700
Epoch 33, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.0237e-03 | Validation Loss : 1.0914e-02
Training CC : 0.9816 | Validation CC : 0.9594
** Classification Losses **
Training Loss : 1.6386e-01 | Validation Loss : 8.2613e-01
Training F1 Macro: 0.8744 | Validation F1 Macro : 0.6899
Training F1 Micro: 0.8916 | Validation F1 Micro : 0.6880
Epoch 34, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.2525e-03 | Validation Loss : 1.0958e-02
Training CC : 0.9816 | Validation CC : 0.9592
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.2938e-01 | Validation Loss : 8.4086e-01
Training F1 Macro: 0.9165 | Validation F1 Macro : 0.6486
Training F1 Micro: 0.9256 | Validation F1 Micro : 0.6500
Epoch 34, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.4826e-03 | Validation Loss : 1.1001e-02
Training CC : 0.9811 | Validation CC : 0.9590
** Classification Losses ** <---- Now Optimizing
Training Loss : 9.2004e-02 | Validation Loss : 8.3908e-01
Training F1 Macro: 0.9551 | Validation F1 Macro : 0.6436
Training F1 Micro: 0.9610 | Validation F1 Micro : 0.6460
Epoch 34, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.2060e-03 | Validation Loss : 1.1070e-02
Training CC : 0.9815 | Validation CC : 0.9588
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.1355e-01 | Validation Loss : 8.4285e-01
Training F1 Macro: 0.8472 | Validation F1 Macro : 0.6510
Training F1 Micro: 0.8849 | Validation F1 Micro : 0.6520
Epoch 34, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.4988e-03 | Validation Loss : 1.1142e-02
Training CC : 0.9807 | Validation CC : 0.9585
** Classification Losses ** <---- Now Optimizing
Training Loss : 8.8868e-02 | Validation Loss : 8.3758e-01
Training F1 Macro: 0.9612 | Validation F1 Macro : 0.6711
Training F1 Micro: 0.9598 | Validation F1 Micro : 0.6740
Epoch 34, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.3507e-03 | Validation Loss : 1.1204e-02
Training CC : 0.9809 | Validation CC : 0.9582
** Classification Losses ** <---- Now Optimizing
Training Loss : 9.3302e-02 | Validation Loss : 8.3785e-01
Training F1 Macro: 0.9596 | Validation F1 Macro : 0.6738
Training F1 Micro: 0.9610 | Validation F1 Micro : 0.6740
Epoch 35, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.4528e-03 | Validation Loss : 1.1062e-02
Training CC : 0.9808 | Validation CC : 0.9592
** Classification Losses **
Training Loss : 1.3513e-01 | Validation Loss : 8.2246e-01
Training F1 Macro: 0.9206 | Validation F1 Macro : 0.6680
Training F1 Micro: 0.9316 | Validation F1 Micro : 0.6680
Epoch 35, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.2868e-03 | Validation Loss : 1.1098e-02
Training CC : 0.9812 | Validation CC : 0.9589
** Classification Losses **
Training Loss : 1.1932e-01 | Validation Loss : 8.1787e-01
Training F1 Macro: 0.8695 | Validation F1 Macro : 0.6692
Training F1 Micro: 0.9305 | Validation F1 Micro : 0.6720
Epoch 35, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.1780e-03 | Validation Loss : 1.0840e-02
Training CC : 0.9816 | Validation CC : 0.9595
** Classification Losses **
Training Loss : 1.3744e-01 | Validation Loss : 8.6061e-01
Training F1 Macro: 0.9094 | Validation F1 Macro : 0.6458
Training F1 Micro: 0.9227 | Validation F1 Micro : 0.6440
Epoch 35, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.9555e-03 | Validation Loss : 1.0792e-02
Training CC : 0.9822 | Validation CC : 0.9601
** Classification Losses **
Training Loss : 1.8142e-01 | Validation Loss : 8.3650e-01
Training F1 Macro: 0.9169 | Validation F1 Macro : 0.6746
Training F1 Micro: 0.9196 | Validation F1 Micro : 0.6740
Epoch 35, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.7285e-03 | Validation Loss : 1.0895e-02
Training CC : 0.9828 | Validation CC : 0.9600
** Classification Losses **
Training Loss : 7.7013e-02 | Validation Loss : 8.3874e-01
Training F1 Macro: 0.9728 | Validation F1 Macro : 0.6737
Training F1 Micro: 0.9789 | Validation F1 Micro : 0.6740
Epoch 36, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.1461e-03 | Validation Loss : 1.0959e-02
Training CC : 0.9821 | Validation CC : 0.9598
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.9280e-01 | Validation Loss : 8.2796e-01
Training F1 Macro: 0.9225 | Validation F1 Macro : 0.6744
Training F1 Micro: 0.9094 | Validation F1 Micro : 0.6740
Epoch 36, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.6800e-03 | Validation Loss : 1.1036e-02
Training CC : 0.9829 | Validation CC : 0.9595
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.3934e-01 | Validation Loss : 8.6659e-01
Training F1 Macro: 0.9401 | Validation F1 Macro : 0.6448
Training F1 Micro: 0.9454 | Validation F1 Micro : 0.6440
Epoch 36, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.9012e-03 | Validation Loss : 1.1089e-02
Training CC : 0.9823 | Validation CC : 0.9593
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.6569e-01 | Validation Loss : 8.9709e-01
Training F1 Macro: 0.9130 | Validation F1 Macro : 0.6372
Training F1 Micro: 0.9113 | Validation F1 Micro : 0.6440
Epoch 36, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.9792e-03 | Validation Loss : 1.1180e-02
Training CC : 0.9820 | Validation CC : 0.9589
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.2410e-01 | Validation Loss : 9.3277e-01
Training F1 Macro: 0.9284 | Validation F1 Macro : 0.6348
Training F1 Micro: 0.9260 | Validation F1 Micro : 0.6380
Epoch 36, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.2045e-03 | Validation Loss : 1.1218e-02
Training CC : 0.9814 | Validation CC : 0.9587
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.0852e-01 | Validation Loss : 9.1714e-01
Training F1 Macro: 0.9738 | Validation F1 Macro : 0.6270
Training F1 Micro: 0.9808 | Validation F1 Micro : 0.6300
Epoch 37, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.9601e-03 | Validation Loss : 1.0922e-02
Training CC : 0.9821 | Validation CC : 0.9594
** Classification Losses **
Training Loss : 1.1953e-01 | Validation Loss : 8.9719e-01
Training F1 Macro: 0.9251 | Validation F1 Macro : 0.6279
Training F1 Micro: 0.9465 | Validation F1 Micro : 0.6300
Epoch 37, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.9759e-03 | Validation Loss : 1.1075e-02
Training CC : 0.9824 | Validation CC : 0.9593
** Classification Losses **
Training Loss : 1.0380e-01 | Validation Loss : 8.4152e-01
Training F1 Macro: 0.9585 | Validation F1 Macro : 0.6540
Training F1 Micro: 0.9562 | Validation F1 Micro : 0.6580
Epoch 37, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.6573e-03 | Validation Loss : 1.0847e-02
Training CC : 0.9831 | Validation CC : 0.9596
** Classification Losses **
Training Loss : 1.6125e-01 | Validation Loss : 8.2798e-01
Training F1 Macro: 0.9458 | Validation F1 Macro : 0.6676
Training F1 Micro: 0.9377 | Validation F1 Micro : 0.6700
Epoch 37, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.9003e-03 | Validation Loss : 1.0743e-02
Training CC : 0.9825 | Validation CC : 0.9602
** Classification Losses **
Training Loss : 1.7077e-01 | Validation Loss : 8.3667e-01
Training F1 Macro: 0.9017 | Validation F1 Macro : 0.6774
Training F1 Micro: 0.9174 | Validation F1 Micro : 0.6780
Epoch 37, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.7685e-03 | Validation Loss : 1.0608e-02
Training CC : 0.9832 | Validation CC : 0.9603
** Classification Losses **
Training Loss : 5.6553e-02 | Validation Loss : 8.3683e-01
Training F1 Macro: 0.9661 | Validation F1 Macro : 0.6776
Training F1 Micro: 0.9718 | Validation F1 Micro : 0.6800
Epoch 38, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.5170e-03 | Validation Loss : 1.0675e-02
Training CC : 0.9837 | Validation CC : 0.9600
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.2985e-01 | Validation Loss : 9.0631e-01
Training F1 Macro: 0.9555 | Validation F1 Macro : 0.6193
Training F1 Micro: 0.9611 | Validation F1 Micro : 0.6240
Epoch 38, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.7287e-03 | Validation Loss : 1.0858e-02
Training CC : 0.9831 | Validation CC : 0.9593
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.7159e-01 | Validation Loss : 9.4132e-01
Training F1 Macro: 0.8815 | Validation F1 Macro : 0.6139
Training F1 Micro: 0.8859 | Validation F1 Micro : 0.6180
Epoch 38, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.8618e-03 | Validation Loss : 1.0875e-02
Training CC : 0.9824 | Validation CC : 0.9593
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.8937e-01 | Validation Loss : 9.0618e-01
Training F1 Macro: 0.8927 | Validation F1 Macro : 0.6224
Training F1 Micro: 0.8929 | Validation F1 Micro : 0.6280
Epoch 38, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.0636e-03 | Validation Loss : 1.0983e-02
Training CC : 0.9815 | Validation CC : 0.9589
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.6501e-01 | Validation Loss : 8.6435e-01
Training F1 Macro: 0.9261 | Validation F1 Macro : 0.6551
Training F1 Micro: 0.9309 | Validation F1 Micro : 0.6560
Epoch 38, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.6307e-03 | Validation Loss : 1.1079e-02
Training CC : 0.9802 | Validation CC : 0.9585
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.0520e-01 | Validation Loss : 8.1722e-01
Training F1 Macro: 0.8836 | Validation F1 Macro : 0.6411
Training F1 Micro: 0.8921 | Validation F1 Micro : 0.6360
Epoch 39, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.2603e-03 | Validation Loss : 1.0959e-02
Training CC : 0.9811 | Validation CC : 0.9598
** Classification Losses **
Training Loss : 1.6613e-01 | Validation Loss : 8.6599e-01
Training F1 Macro: 0.9382 | Validation F1 Macro : 0.6021
Training F1 Micro: 0.9363 | Validation F1 Micro : 0.6020
Epoch 39, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.0251e-03 | Validation Loss : 1.0636e-02
Training CC : 0.9820 | Validation CC : 0.9607
** Classification Losses **
Training Loss : 1.2532e-01 | Validation Loss : 8.6399e-01
Training F1 Macro: 0.9486 | Validation F1 Macro : 0.6307
Training F1 Micro: 0.9521 | Validation F1 Micro : 0.6300
Epoch 39, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.8521e-03 | Validation Loss : 1.1108e-02
Training CC : 0.9826 | Validation CC : 0.9589
** Classification Losses **
Training Loss : 9.6658e-02 | Validation Loss : 8.4316e-01
Training F1 Macro: 0.9549 | Validation F1 Macro : 0.6334
Training F1 Micro: 0.9636 | Validation F1 Micro : 0.6340
Epoch 39, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.9373e-03 | Validation Loss : 1.0532e-02
Training CC : 0.9824 | Validation CC : 0.9610
** Classification Losses **
Training Loss : 1.8196e-01 | Validation Loss : 8.3149e-01
Training F1 Macro: 0.8737 | Validation F1 Macro : 0.6511
Training F1 Micro: 0.8893 | Validation F1 Micro : 0.6540
Epoch 39, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.3936e-03 | Validation Loss : 1.0513e-02
Training CC : 0.9840 | Validation CC : 0.9613
** Classification Losses **
Training Loss : 2.0105e-01 | Validation Loss : 8.4996e-01
Training F1 Macro: 0.9282 | Validation F1 Macro : 0.6522
Training F1 Micro: 0.9309 | Validation F1 Micro : 0.6520
Epoch 40, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.3714e-03 | Validation Loss : 1.0631e-02
Training CC : 0.9842 | Validation CC : 0.9609
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.0793e-01 | Validation Loss : 8.2760e-01
Training F1 Macro: 0.9235 | Validation F1 Macro : 0.6619
Training F1 Micro: 0.9368 | Validation F1 Micro : 0.6640
Epoch 40, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.5324e-03 | Validation Loss : 1.0775e-02
Training CC : 0.9836 | Validation CC : 0.9603
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.1126e-01 | Validation Loss : 8.3987e-01
Training F1 Macro: 0.9561 | Validation F1 Macro : 0.6651
Training F1 Micro: 0.9558 | Validation F1 Micro : 0.6680
Epoch 40, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.0310e-03 | Validation Loss : 1.0854e-02
Training CC : 0.9825 | Validation CC : 0.9600
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.1347e-01 | Validation Loss : 8.3808e-01
Training F1 Macro: 0.9488 | Validation F1 Macro : 0.6586
Training F1 Micro: 0.9403 | Validation F1 Micro : 0.6580
Epoch 40, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.8466e-03 | Validation Loss : 1.0899e-02
Training CC : 0.9828 | Validation CC : 0.9599
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.1705e-01 | Validation Loss : 8.5866e-01
Training F1 Macro: 0.9330 | Validation F1 Macro : 0.6414
Training F1 Micro: 0.9385 | Validation F1 Micro : 0.6420
Epoch 40, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.1352e-03 | Validation Loss : 1.0945e-02
Training CC : 0.9821 | Validation CC : 0.9597
** Classification Losses ** <---- Now Optimizing
Training Loss : 6.6949e-02 | Validation Loss : 8.4555e-01
Training F1 Macro: 0.9718 | Validation F1 Macro : 0.6398
Training F1 Micro: 0.9793 | Validation F1 Micro : 0.6420
Epoch 41, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.0206e-03 | Validation Loss : 1.0775e-02
Training CC : 0.9825 | Validation CC : 0.9599
** Classification Losses **
Training Loss : 6.1587e-02 | Validation Loss : 8.3481e-01
Training F1 Macro: 0.9618 | Validation F1 Macro : 0.6703
Training F1 Micro: 0.9707 | Validation F1 Micro : 0.6700
Epoch 41, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.6551e-03 | Validation Loss : 1.0587e-02
Training CC : 0.9834 | Validation CC : 0.9607
** Classification Losses **
Training Loss : 1.6079e-01 | Validation Loss : 8.4015e-01
Training F1 Macro: 0.9110 | Validation F1 Macro : 0.6451
Training F1 Micro: 0.9175 | Validation F1 Micro : 0.6440
Epoch 41, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.4449e-03 | Validation Loss : 1.0927e-02
Training CC : 0.9820 | Validation CC : 0.9604
** Classification Losses **
Training Loss : 1.1766e-01 | Validation Loss : 8.0699e-01
Training F1 Macro: 0.8826 | Validation F1 Macro : 0.6785
Training F1 Micro: 0.9401 | Validation F1 Micro : 0.6780
Epoch 41, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.0031e-03 | Validation Loss : 1.0790e-02
Training CC : 0.9827 | Validation CC : 0.9595
** Classification Losses **
Training Loss : 1.9159e-01 | Validation Loss : 8.1177e-01
Training F1 Macro: 0.9110 | Validation F1 Macro : 0.6700
Training F1 Micro: 0.9144 | Validation F1 Micro : 0.6700
Epoch 41, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.7549e-03 | Validation Loss : 1.0733e-02
Training CC : 0.9832 | Validation CC : 0.9610
** Classification Losses **
Training Loss : 1.0062e-01 | Validation Loss : 8.1848e-01
Training F1 Macro: 0.9293 | Validation F1 Macro : 0.6452
Training F1 Micro: 0.9408 | Validation F1 Micro : 0.6440
Epoch 42, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.7192e-03 | Validation Loss : 1.0761e-02
Training CC : 0.9833 | Validation CC : 0.9609
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.2545e-01 | Validation Loss : 8.0116e-01
Training F1 Macro: 0.9525 | Validation F1 Macro : 0.6719
Training F1 Micro: 0.9607 | Validation F1 Micro : 0.6720
Epoch 42, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.6895e-03 | Validation Loss : 1.0768e-02
Training CC : 0.9833 | Validation CC : 0.9608
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.0419e-01 | Validation Loss : 8.5228e-01
Training F1 Macro: 0.9140 | Validation F1 Macro : 0.6441
Training F1 Micro: 0.9109 | Validation F1 Micro : 0.6480
Epoch 42, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.5664e-03 | Validation Loss : 1.0793e-02
Training CC : 0.9835 | Validation CC : 0.9607
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.2569e-01 | Validation Loss : 8.6683e-01
Training F1 Macro: 0.9439 | Validation F1 Macro : 0.6389
Training F1 Micro: 0.9428 | Validation F1 Micro : 0.6400
Epoch 42, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.7742e-03 | Validation Loss : 1.0817e-02
Training CC : 0.9830 | Validation CC : 0.9606
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.5519e-01 | Validation Loss : 8.6825e-01
Training F1 Macro: 0.8402 | Validation F1 Macro : 0.6371
Training F1 Micro: 0.9062 | Validation F1 Micro : 0.6380
Epoch 42, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.4573e-03 | Validation Loss : 1.0842e-02
Training CC : 0.9818 | Validation CC : 0.9605
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.3222e-01 | Validation Loss : 8.4281e-01
Training F1 Macro: 0.8828 | Validation F1 Macro : 0.6519
Training F1 Micro: 0.9201 | Validation F1 Micro : 0.6540
Epoch 43, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.6141e-03 | Validation Loss : 1.0668e-02
Training CC : 0.9833 | Validation CC : 0.9600
** Classification Losses **
Training Loss : 1.3341e-01 | Validation Loss : 8.5130e-01
Training F1 Macro: 0.9226 | Validation F1 Macro : 0.6170
Training F1 Micro: 0.9202 | Validation F1 Micro : 0.6180
Epoch 43, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.8731e-03 | Validation Loss : 1.0793e-02
Training CC : 0.9831 | Validation CC : 0.9609
** Classification Losses **
Training Loss : 1.2119e-01 | Validation Loss : 8.3863e-01
Training F1 Macro: 0.9338 | Validation F1 Macro : 0.6459
Training F1 Micro: 0.9336 | Validation F1 Micro : 0.6480
Epoch 43, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.8705e-03 | Validation Loss : 1.0652e-02
Training CC : 0.9832 | Validation CC : 0.9602
** Classification Losses **
Training Loss : 8.4504e-02 | Validation Loss : 8.2068e-01
Training F1 Macro: 0.9721 | Validation F1 Macro : 0.6556
Training F1 Micro: 0.9738 | Validation F1 Micro : 0.6540
Epoch 43, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.8990e-03 | Validation Loss : 1.0347e-02
Training CC : 0.9829 | Validation CC : 0.9618
** Classification Losses **
Training Loss : 1.8049e-01 | Validation Loss : 8.2925e-01
Training F1 Macro: 0.9013 | Validation F1 Macro : 0.6451
Training F1 Micro: 0.9113 | Validation F1 Micro : 0.6460
Epoch 43, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.7190e-03 | Validation Loss : 1.0913e-02
Training CC : 0.9835 | Validation CC : 0.9602
** Classification Losses **
Training Loss : 1.5133e-01 | Validation Loss : 8.1947e-01
Training F1 Macro: 0.9246 | Validation F1 Macro : 0.6669
Training F1 Micro: 0.9209 | Validation F1 Micro : 0.6660
Epoch 44, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.8816e-03 | Validation Loss : 1.0973e-02
Training CC : 0.9825 | Validation CC : 0.9600
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.9837e-01 | Validation Loss : 8.3893e-01
Training F1 Macro: 0.9208 | Validation F1 Macro : 0.6379
Training F1 Micro: 0.9192 | Validation F1 Micro : 0.6360
Epoch 44, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.0027e-03 | Validation Loss : 1.1031e-02
Training CC : 0.9823 | Validation CC : 0.9598
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.2891e-01 | Validation Loss : 8.5044e-01
Training F1 Macro: 0.9255 | Validation F1 Macro : 0.6440
Training F1 Micro: 0.9319 | Validation F1 Micro : 0.6480
Epoch 44, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.0973e-03 | Validation Loss : 1.1041e-02
Training CC : 0.9820 | Validation CC : 0.9597
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.4647e-01 | Validation Loss : 8.7057e-01
Training F1 Macro: 0.9091 | Validation F1 Macro : 0.6347
Training F1 Micro: 0.9126 | Validation F1 Micro : 0.6380
Epoch 44, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.9818e-03 | Validation Loss : 1.1052e-02
Training CC : 0.9821 | Validation CC : 0.9597
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.9880e-01 | Validation Loss : 9.0095e-01
Training F1 Macro: 0.8668 | Validation F1 Macro : 0.6402
Training F1 Micro: 0.8772 | Validation F1 Micro : 0.6440
Epoch 44, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.9188e-03 | Validation Loss : 1.1133e-02
Training CC : 0.9822 | Validation CC : 0.9593
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.7464e-01 | Validation Loss : 8.5808e-01
Training F1 Macro: 0.9069 | Validation F1 Macro : 0.6363
Training F1 Micro: 0.9040 | Validation F1 Micro : 0.6380
Epoch 45, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.6926e-03 | Validation Loss : 1.0841e-02
Training CC : 0.9829 | Validation CC : 0.9596
** Classification Losses **
Training Loss : 1.9387e-01 | Validation Loss : 8.3898e-01
Training F1 Macro: 0.9030 | Validation F1 Macro : 0.6428
Training F1 Micro: 0.9013 | Validation F1 Micro : 0.6440
Epoch 45, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 5.1664e-03 | Validation Loss : 1.0579e-02
Training CC : 0.9827 | Validation CC : 0.9610
** Classification Losses **
Training Loss : 9.5003e-02 | Validation Loss : 8.5743e-01
Training F1 Macro: 0.9628 | Validation F1 Macro : 0.6361
Training F1 Micro: 0.9622 | Validation F1 Micro : 0.6380
Epoch 45, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.7512e-03 | Validation Loss : 1.0441e-02
Training CC : 0.9837 | Validation CC : 0.9617
** Classification Losses **
Training Loss : 1.5454e-01 | Validation Loss : 8.2257e-01
Training F1 Macro: 0.9505 | Validation F1 Macro : 0.6542
Training F1 Micro: 0.9413 | Validation F1 Micro : 0.6560
Epoch 45, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.7732e-03 | Validation Loss : 1.0324e-02
Training CC : 0.9839 | Validation CC : 0.9615
** Classification Losses **
Training Loss : 1.3215e-01 | Validation Loss : 8.3647e-01
Training F1 Macro: 0.9379 | Validation F1 Macro : 0.6712
Training F1 Micro: 0.9450 | Validation F1 Micro : 0.6720
Epoch 45, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.4199e-03 | Validation Loss : 1.0442e-02
Training CC : 0.9846 | Validation CC : 0.9620
** Classification Losses **
Training Loss : 2.0394e-01 | Validation Loss : 8.5028e-01
Training F1 Macro: 0.8702 | Validation F1 Macro : 0.6474
Training F1 Micro: 0.9086 | Validation F1 Micro : 0.6480
Epoch 46, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.2274e-03 | Validation Loss : 1.0442e-02
Training CC : 0.9849 | Validation CC : 0.9620
** Classification Losses ** <---- Now Optimizing
Training Loss : 7.5148e-02 | Validation Loss : 8.2594e-01
Training F1 Macro: 0.9694 | Validation F1 Macro : 0.6511
Training F1 Micro: 0.9656 | Validation F1 Micro : 0.6520
Epoch 46, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.1581e-03 | Validation Loss : 1.0478e-02
Training CC : 0.9850 | Validation CC : 0.9618
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.6482e-01 | Validation Loss : 8.3136e-01
Training F1 Macro: 0.9453 | Validation F1 Macro : 0.6472
Training F1 Micro: 0.9397 | Validation F1 Micro : 0.6460
Epoch 46, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.8056e-03 | Validation Loss : 1.0535e-02
Training CC : 0.9837 | Validation CC : 0.9616
** Classification Losses ** <---- Now Optimizing
Training Loss : 9.3537e-02 | Validation Loss : 8.4890e-01
Training F1 Macro: 0.9483 | Validation F1 Macro : 0.6506
Training F1 Micro: 0.9445 | Validation F1 Micro : 0.6520
Epoch 46, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.4704e-03 | Validation Loss : 1.0588e-02
Training CC : 0.9842 | Validation CC : 0.9614
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.4201e-01 | Validation Loss : 8.7496e-01
Training F1 Macro: 0.9118 | Validation F1 Macro : 0.6434
Training F1 Micro: 0.9259 | Validation F1 Micro : 0.6440
Epoch 46, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.0832e-03 | Validation Loss : 1.0632e-02
Training CC : 0.9830 | Validation CC : 0.9612
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.7735e-01 | Validation Loss : 8.1682e-01
Training F1 Macro: 0.8929 | Validation F1 Macro : 0.6656
Training F1 Micro: 0.9016 | Validation F1 Micro : 0.6660
Epoch 47, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.7115e-03 | Validation Loss : 1.0414e-02
Training CC : 0.9836 | Validation CC : 0.9609
** Classification Losses **
Training Loss : 1.6110e-01 | Validation Loss : 8.0459e-01
Training F1 Macro: 0.9162 | Validation F1 Macro : 0.6898
Training F1 Micro: 0.9203 | Validation F1 Micro : 0.6900
Epoch 47, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.9191e-03 | Validation Loss : 1.0584e-02
Training CC : 0.9835 | Validation CC : 0.9612
** Classification Losses **
Training Loss : 1.2861e-01 | Validation Loss : 7.9698e-01
Training F1 Macro: 0.9240 | Validation F1 Macro : 0.6807
Training F1 Micro: 0.9358 | Validation F1 Micro : 0.6820
Epoch 47, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.4314e-03 | Validation Loss : 1.0281e-02
Training CC : 0.9843 | Validation CC : 0.9614
** Classification Losses **
Training Loss : 1.2555e-01 | Validation Loss : 8.0330e-01
Training F1 Macro: 0.9406 | Validation F1 Macro : 0.6758
Training F1 Micro: 0.9392 | Validation F1 Micro : 0.6780
Epoch 47, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.1539e-03 | Validation Loss : 1.0315e-02
Training CC : 0.9851 | Validation CC : 0.9621
** Classification Losses **
Training Loss : 1.5740e-01 | Validation Loss : 8.3603e-01
Training F1 Macro: 0.9242 | Validation F1 Macro : 0.6553
Training F1 Micro: 0.9165 | Validation F1 Micro : 0.6560
Epoch 47, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.1587e-03 | Validation Loss : 1.0259e-02
Training CC : 0.9851 | Validation CC : 0.9620
** Classification Losses **
Training Loss : 1.3513e-01 | Validation Loss : 8.2075e-01
Training F1 Macro: 0.9522 | Validation F1 Macro : 0.6599
Training F1 Micro: 0.9481 | Validation F1 Micro : 0.6620
Epoch 48, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 5.0984e-03 | Validation Loss : 1.0284e-02
Training CC : 0.9837 | Validation CC : 0.9619
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.5428e-01 | Validation Loss : 8.4205e-01
Training F1 Macro: 0.9212 | Validation F1 Macro : 0.6582
Training F1 Micro: 0.9193 | Validation F1 Micro : 0.6580
Epoch 48, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.2070e-03 | Validation Loss : 1.0380e-02
Training CC : 0.9851 | Validation CC : 0.9615
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.0655e-01 | Validation Loss : 8.7972e-01
Training F1 Macro: 0.9440 | Validation F1 Macro : 0.6316
Training F1 Micro: 0.9431 | Validation F1 Micro : 0.6300
Epoch 48, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.1873e-03 | Validation Loss : 1.0472e-02
Training CC : 0.9848 | Validation CC : 0.9612
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.3877e-01 | Validation Loss : 9.0709e-01
Training F1 Macro: 0.9201 | Validation F1 Macro : 0.6334
Training F1 Micro: 0.9193 | Validation F1 Micro : 0.6360
Epoch 48, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.5383e-03 | Validation Loss : 1.0566e-02
Training CC : 0.9840 | Validation CC : 0.9608
** Classification Losses ** <---- Now Optimizing
Training Loss : 5.0548e-02 | Validation Loss : 8.8953e-01
Training F1 Macro: 0.9704 | Validation F1 Macro : 0.6262
Training F1 Micro: 0.9684 | Validation F1 Micro : 0.6280
Epoch 48, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.5758e-03 | Validation Loss : 1.0665e-02
Training CC : 0.9837 | Validation CC : 0.9605
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.2311e-01 | Validation Loss : 8.5462e-01
Training F1 Macro: 0.9548 | Validation F1 Macro : 0.6509
Training F1 Micro: 0.9498 | Validation F1 Micro : 0.6540
Epoch 49, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.2710e-03 | Validation Loss : 1.0405e-02
Training CC : 0.9846 | Validation CC : 0.9618
** Classification Losses **
Training Loss : 9.7918e-02 | Validation Loss : 8.3508e-01
Training F1 Macro: 0.9648 | Validation F1 Macro : 0.6521
Training F1 Micro: 0.9609 | Validation F1 Micro : 0.6520
Epoch 49, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.4393e-03 | Validation Loss : 1.0249e-02
Training CC : 0.9846 | Validation CC : 0.9620
** Classification Losses **
Training Loss : 9.5729e-02 | Validation Loss : 8.3707e-01
Training F1 Macro: 0.9763 | Validation F1 Macro : 0.6573
Training F1 Micro: 0.9713 | Validation F1 Micro : 0.6580
Epoch 49, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 3.9717e-03 | Validation Loss : 1.0230e-02
Training CC : 0.9855 | Validation CC : 0.9622
** Classification Losses **
Training Loss : 1.1090e-01 | Validation Loss : 8.3701e-01
Training F1 Macro: 0.9384 | Validation F1 Macro : 0.6700
Training F1 Micro: 0.9534 | Validation F1 Micro : 0.6740
Epoch 49, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 3.9482e-03 | Validation Loss : 1.0100e-02
Training CC : 0.9857 | Validation CC : 0.9626
** Classification Losses **
Training Loss : 1.9180e-01 | Validation Loss : 8.3105e-01
Training F1 Macro: 0.8536 | Validation F1 Macro : 0.6627
Training F1 Micro: 0.8889 | Validation F1 Micro : 0.6640
Epoch 49, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses ** <---- Now Optimizing
Training Loss : 4.1349e-03 | Validation Loss : 1.0093e-02
Training CC : 0.9857 | Validation CC : 0.9631
** Classification Losses **
Training Loss : 1.1157e-01 | Validation Loss : 8.3514e-01
Training F1 Macro: 0.9467 | Validation F1 Macro : 0.6570
Training F1 Micro: 0.9421 | Validation F1 Micro : 0.6580
Epoch 50, of 50 >-*-< Mini Epoch 1 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 3.7945e-03 | Validation Loss : 1.0133e-02
Training CC : 0.9863 | Validation CC : 0.9630
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.2635e-01 | Validation Loss : 8.5252e-01
Training F1 Macro: 0.9090 | Validation F1 Macro : 0.6538
Training F1 Micro: 0.9208 | Validation F1 Micro : 0.6540
Epoch 50, of 50 >-*-< Mini Epoch 2 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 3.8101e-03 | Validation Loss : 1.0200e-02
Training CC : 0.9862 | Validation CC : 0.9627
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.4358e-01 | Validation Loss : 8.3129e-01
Training F1 Macro: 0.8696 | Validation F1 Macro : 0.6547
Training F1 Micro: 0.8716 | Validation F1 Micro : 0.6580
Epoch 50, of 50 >-*-< Mini Epoch 3 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 3.9694e-03 | Validation Loss : 1.0274e-02
Training CC : 0.9858 | Validation CC : 0.9624
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.3971e-01 | Validation Loss : 8.3678e-01
Training F1 Macro: 0.9404 | Validation F1 Macro : 0.6499
Training F1 Micro: 0.9438 | Validation F1 Micro : 0.6520
Epoch 50, of 50 >-*-< Mini Epoch 4 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.0473e-03 | Validation Loss : 1.0330e-02
Training CC : 0.9855 | Validation CC : 0.9622
** Classification Losses ** <---- Now Optimizing
Training Loss : 1.3552e-01 | Validation Loss : 8.4466e-01
Training F1 Macro: 0.9542 | Validation F1 Macro : 0.6262
Training F1 Micro: 0.9540 | Validation F1 Micro : 0.6260
Epoch 50, of 50 >-*-< Mini Epoch 5 of 5 >-*-< Learning rate 1.000e-03
** Autoencoding Losses **
Training Loss : 4.3496e-03 | Validation Loss : 1.0414e-02
Training CC : 0.9848 | Validation CC : 0.9619
** Classification Losses ** <---- Now Optimizing
Training Loss : 2.8723e-02 | Validation Loss : 8.0752e-01
Training F1 Macro: 0.9779 | Validation F1 Macro : 0.6700
Training F1 Micro: 0.9814 | Validation F1 Micro : 0.6680
Visualize the loss function progression
[7]:
plots.plot_training_results_segmentation(rv[2]).show()
plots.plot_training_results_regression(rv[1]).show()
We pass over the test data again and collect stuff so we can inspect what is happening.
[8]:
results = []
pres = []
latent = []
true_lbl = []
inp_img = []
for batch in test_loader:
true_lbl.append(batch[1])
with torch.no_grad():
inp_img.append(batch[0].cpu())
res, ps = autoencoder(batch[0].to("cuda:0"))
lt = autoencoder.encode(batch[0].to("cuda:0"))
results.append(res.cpu())
latent.append(lt.cpu())
pres.append(ps.cpu())
results = torch.cat(results, dim=0)
latent = torch.cat(latent, dim=0)
pres = nn.Softmax(1)(torch.cat(pres,dim=0))
true_lbl = torch.cat(true_lbl, dim=0)
inp_img = torch.cat(inp_img, dim=0)
Lets have a look and see what we get; lets make a quick plotting utility.
[9]:
count = 0
for img, cc, tlbl, ori, ltl in zip(results, pres, true_lbl, inp_img, latent):
if True: #tlbl.item() < 0:
paic.plot_autoencoder_and_label_results(input_img=ori.numpy()[0,...],
output_img=img.numpy()[0,...],
p_classification=cc.numpy(),
class_names=["Rectangle","Disc","Triangle","Annulus"])
plt.show()
count += 1
if count > 15:
break
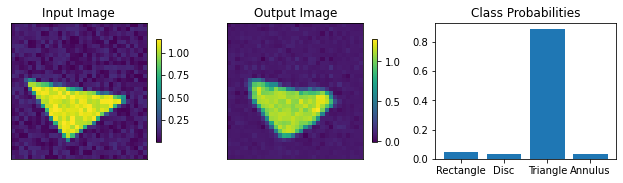
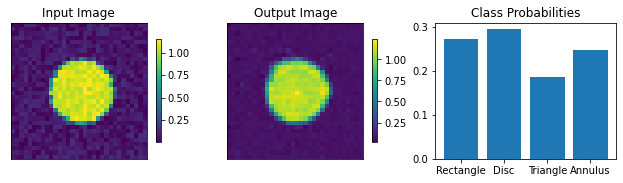
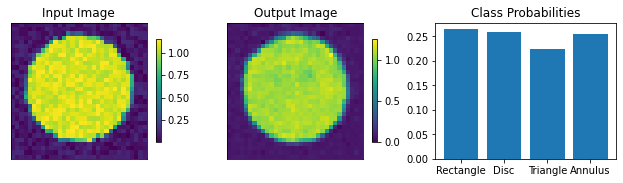

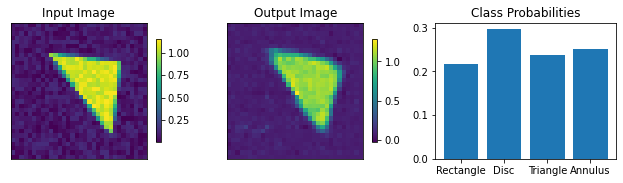
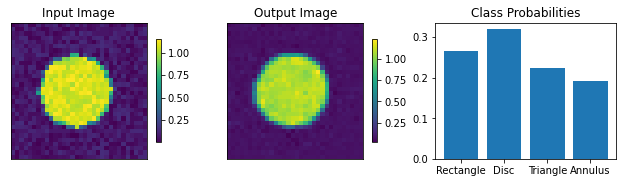
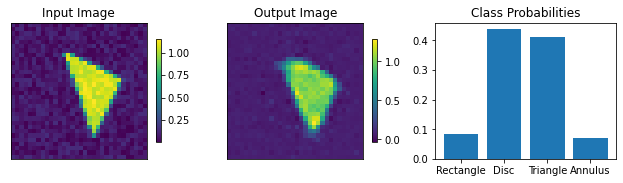
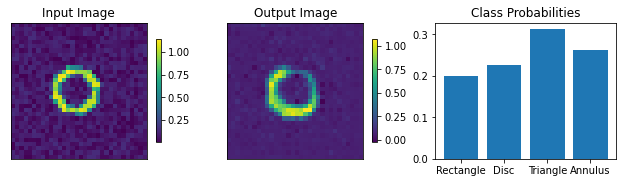
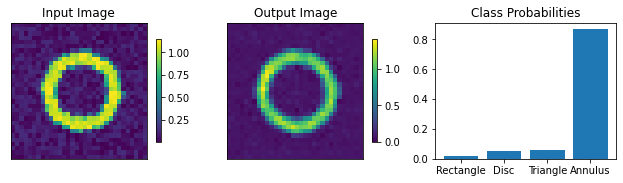
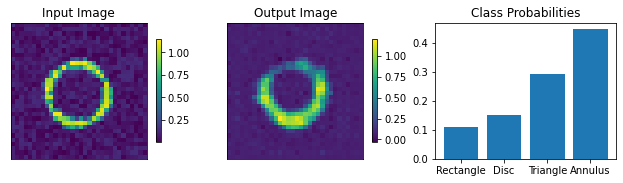
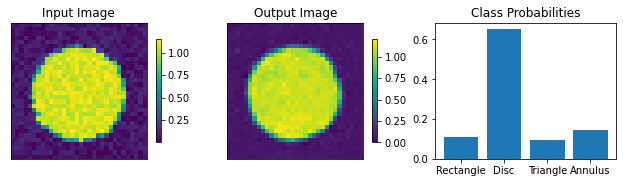
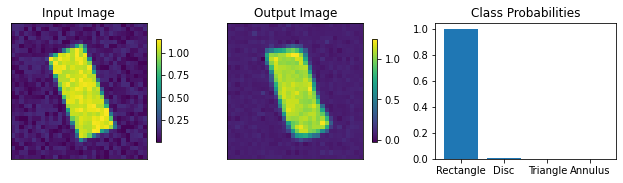
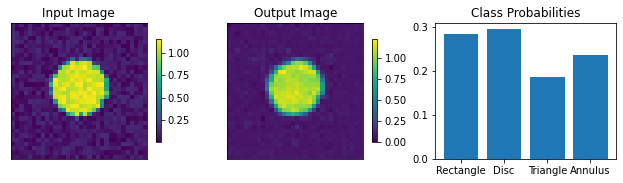
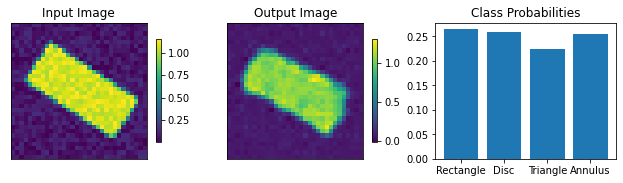
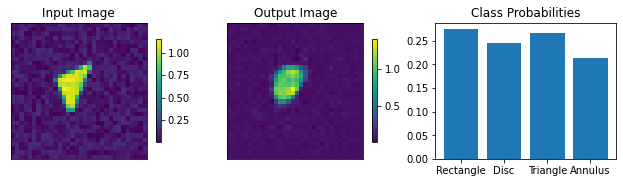
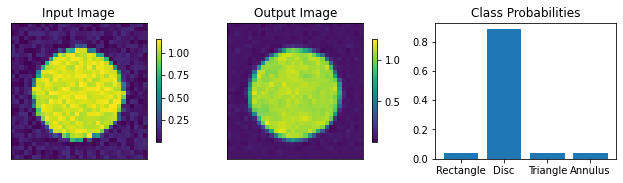
As you see, we are doing reasonably well, but lets inspect the latent space and see whats going on. One can run a PCA / SVD on the latent vectors, but this is not very informative because of the dimensionality of the system. Instead, we run a UMAP and see how things look in 2D.
It is interestiong to re-run the notebook, but without using any labels during optimization. To make this happen, just set the number of epochs to 1 and the number of mini epochs to 100 (or so). In that way, it will not reach the classification minimization. The resulting latent space will be less neat.
[10]:
latent = einops.rearrange(latent, "N C Y X -> N (C Y X)")
umapper = umap.UMAP(min_dist=0, n_neighbors=35)
X = umapper.fit_transform(latent.numpy())
Lets get the labels and see what we have.
We make two plots: First, we show the umapped latent space with the given labels and the unknown labels, and second, we will show the inferred / guessed labels.
[ ]:
[11]:
infered_labels = torch.argmax(pres, dim=1).numpy()+1
for lbl in [0,1,2,3,4]:
sel = true_lbl.numpy()[:,0]+1==lbl
ms=1
if lbl==0:
ms=0.5
plt.plot(X[sel,0], X[sel,1], '.', markersize=ms)
plt.legend(["UNKNOWN","Rectangles","Discs","Triangles","Annuli"])
plt.title("Given labels in latent space")
plt.show()
for lbl in [0,1,2,3,4]:
sel = infered_labels==lbl
ms=1
plt.plot(X[sel,0], X[sel,1], '.', markersize=ms)
plt.legend(["UNKNOWN","Rectangles","Discs","Triangles","Annuli"])
plt.title("Predicted labels in latent space")
plt.show()
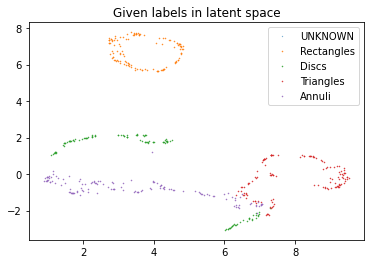
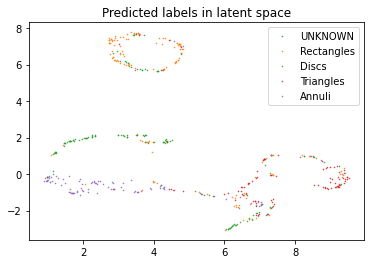
As you can see, we are not perfect, lets have a look at some specific cases
[12]:
count = 0
for img, cc, tlbl, ori, pl in zip(results, pres, true_lbl, inp_img, infered_labels):
if int(tlbl[0]) != pl-1:
paic.plot_autoencoder_and_label_results(input_img=ori.numpy()[0,...],
output_img=img.numpy()[0,...],
p_classification=cc.numpy(),
class_names=["Rectangle","Disc","Triangle","Annulus"])
plt.show()
count += 1
if count > 5:
break
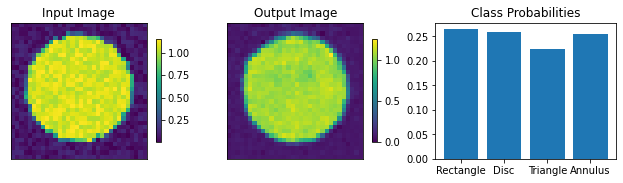
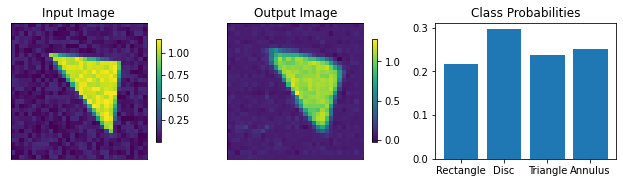
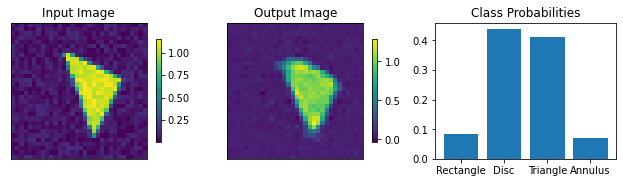
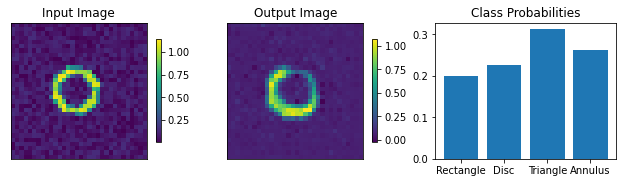
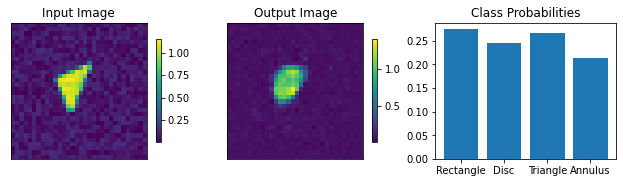
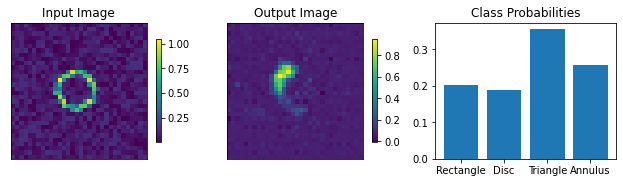
Last but not least, we can view our latent space
[13]:
fig = latent_space_viewer.build_latent_space_image_viewer(inp_img.numpy()[:,0,...],
X,
n_bins=50,
min_count=1,
max_count=1,
mode="nearest")